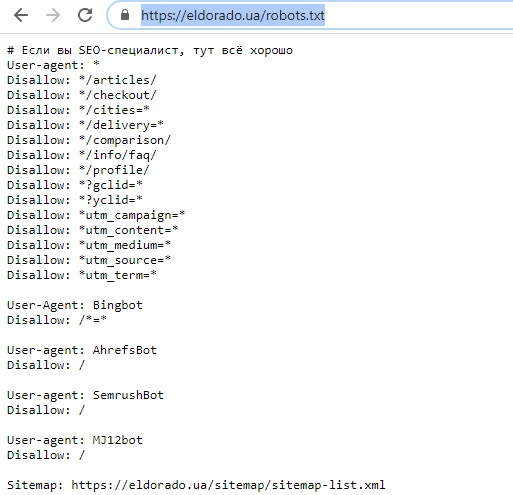
Что такое файл robots.txt
Директивы robots.txt
Директивы robots.txt — это набор инструкций, которыми руководствуются индексирующие роботы при посещении сайта. С их помощью можно закрыть определенные страницы или разделы от индексации, управлять скоростью обхода, указать ссылку на sitemap и т.д. Каждая директива должна прописываться с новой строки. После указания директивы ставиться двоеточие и далее прописывается её параметр.
Рассмотрим директивы подробнее.
User-agent robots txt
Robots txt disallow
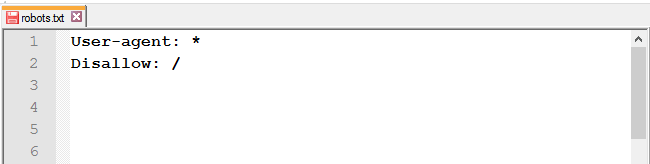
Директива Disallow запрещает веб-краулерам индексировать страницу либо раздел. Наиболее часто используемая инструкция в файле robots.txt. С его помощью можно полностью закрыть сайт от индексации:
User-agent: *
Disallow: /
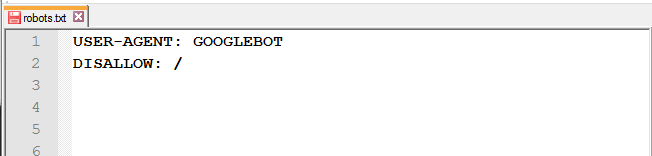
или от конкретного робота поисковой системы:
User-agent: Googlebot
Disallow: /
В качестве параметра следует использовать относительный путь к директории или странице (без указания доменного имени).
Robots txt allow
Директива Allow в robots.txt является разрешающей инструкцией для веб-краулеров. Очень полезна в случае, когда нам необходимо точечно открыть страницы / подразделы в закрытой директории сайта. Например:
User-agent: *
Disallow: /
Allow: /content
В приведенном примере директива Allow принудительно откроет роботам доступ к индексации страниц, начинающихся с /content, при этом весь остальной сайт будет закрыт от индексации.
Важно! Пустой параметр в директиве Allow запрещает индексацию всего сайта:
User-agent: *
Allow:
Clean-param robots txt
Директива Clean-param в robots.txt позволяет исключить из индексации веб-краулерами страницы с динамически генерируемым параметрами в URL. Использование Clean-param в файле robots.txt поможет исключить из индексации дубли страниц, генерирующиеся для реферальных ссылок, UTM-меток, при записи сессий и параметров пользователя.
К примеру мы имеем сгенерированный УРЛы с динамической записью параметра пользователя:
https://site.com/catalog/index.php?&id=1¶m=2
https://site.com/catalog/index.php?&id=2¶m=2
https://site.com/catalog/index.php?&id=3¶m=3
В данном случае нам необходимо составить правило для исключения получившихся параметров. Запись в файле роботс будет такой:
User-agent: *
Clean-Param: &id¶m /catalog/index.php
В результате такой строки индексироваться будет только страница https://site.com/catalog/index.php
С помощью Clean-param можно закрыть от индексации не только отдельные страницы, но и UTM-метки либо идентификаторы пользователей для всего сайта
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-delay robots.txt
Директива Crawl-delay в robots.txt позволяет управлять задержками между запросами веб-краулеров к страницам на веб-сервере. В качестве параметров можно указывать целые числа и десятичные дроби (точка в качестве разделителя). Единица измерения — секунды. Директива Crawl-delay поддерживается роботами Яндекс, Mail.Ru, Bing и Yahoo!.
Используется в случае если сервер не выдерживает частоту обращений поисковых роботов. Актуально в случае, когда веб-ресурс состоит из большого числа страниц и слабом веб-сервере.
Рекомендуется начинать применять минимальные параметры, постепенно их увеличивая при необходимости. Для неприоритетных поисковых систем можно изначально задать параметр «с запасом», чтобы исключить их влияние на стабильность сервера.
Пример:
User-agent: Yandex
Crawl-delay: 0.5
User-agent: Mail.Ru
Crawl-delay: 3
Тут мы задали задержку между запросами для Яндекс в пол секунды, а для Мэйл.ру — 3 секунды.
Robots txt sitemap
Директива Sitemap в robots.txt предназначена для указания пути к XML-файлу Sitemap. В качестве параметра необходимо указывать полный (абсолютный) путь к сайтмап. Указание данной директивы сигнализирует поисковым роботам о наличии карты сайта, что позволяет ускорить обнаружение и индексацию новых страниц. Директива не имеет привязки к конкретному юзер-агенту и может быть указана в любой строке файла роботс. Однако хорошим тоном считается указание сайтмап отдельно от всех директив через пустую строку:
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
User-agent: Googlebot
Allow: /
Sitemap: https://site.com/sitemap.xml
Устаревшая директива Host
До 20 марта 2018 года поисковая система Яндекс использовала директиву Host для определения главного зеркала. На данный момент поисковик не учитывает её и рекомендует пользоваться 301 редиректом. Однако в сети интернет по прежнему можно найти массу сайтов у которых директива Host указана.
User-agent: Yandex
Disallow: /catalog/
Allow: /catalog/index.php
Host: https://site.com
Прочие директивы robots.txt
Спецификация файла роботс содержит две дополнительные директивы:
— Request-rate: 1/3 ограничивает скорость загрузки страниц, не более одной за три секунды (параметры можно задать любые);
— Visit-time: 0815-1000 определяет временной интервал по гринвичу, в который веб-краулерам разрешено индексировать страницы ( в примере это промежуток с 08:15 по 10:00).
Однако на данный момент они не поддерживаются ведущими поисковыми системами и их использование не имеет смысла.
Использование регулярных выражений
В файле robots.txt для более гибкой настройки параметров директив часто используются спецсимволы, которые значительно расширяют функционал. К ним относятся:
1. * (звездочка) определяет любую последовательность символов в том месте, где она указана.
В конце строки звездочка не обязательна, т.к. роботы предполагают её наличие по умолчанию.
В качестве примера
User-agent: *
Disallow: /catalog/*
Allow: /catalog/*.css
Allow: /catalog/*.php
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
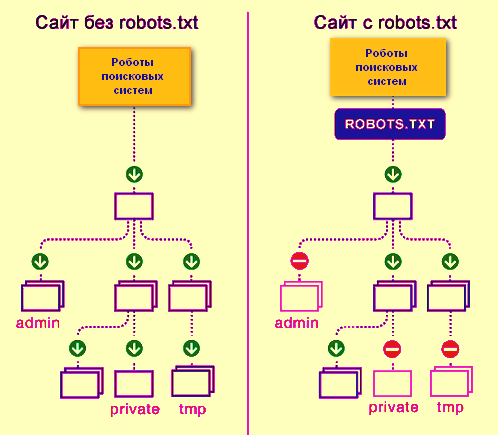
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
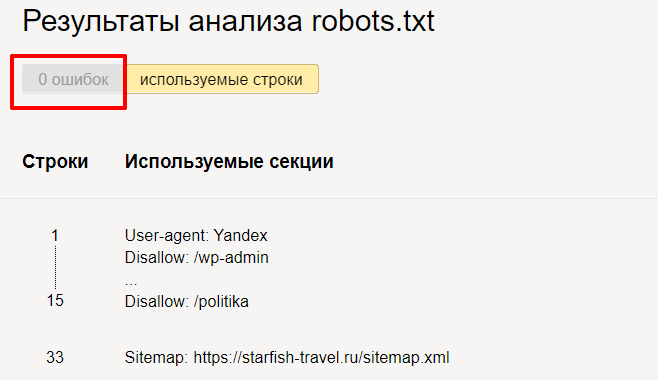
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
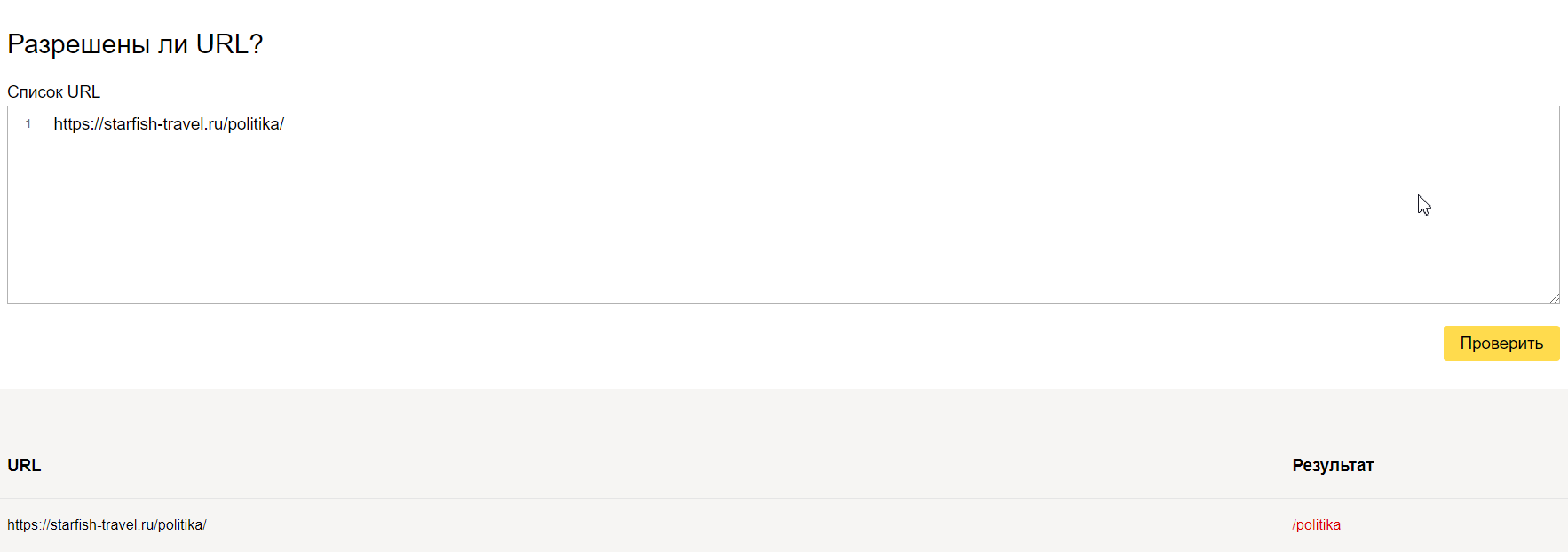
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Гайд по robots.txt: создаём, настраиваем, проверяем
В этой статье мы рассмотрим:
Что такое robots.txt?
Robots.txt — это текстовый файл, который содержит в себе рекомендации для действий поисковых роботов. В этом файле находятся инструкции (директивы), с помощью которых можно ограничить доступ поисковых роботов к определённым папкам, страницам и файлам, задать скорость сканирования сайта, указать главное зеркало или адрес карты сайта.
Обход сайта поисковыми роботами начинается с поиска файла роботс. Отсутствие файла не является критической ошибкой. В таком случае роботы считают, что ограничений для них нет и они полностью могут сканировать сайт.
Файл должен быть размещён в корневом каталоге сайта и быть доступен по адресу https://mysite.com/robots.txt.
Инструкции стандарта исключения для роботов носят рекомендательный характер, а не являются прямыми командами для роботов. То есть существует вероятность, что даже закрыв страницу в robots.txt, она всё равно попадёт в индекс.
Указывать директивы в файле нужно только латиницей, использовать кириллицу запрещено. Русские доменные имена можно преобразовать с помощью кодировки Punycode.

Что нужно закрыть от индексации в robots.txt?
Как создать robots.txt?
Составить файл можно в любом текстовом редакторе (блокнот, TextEdit и др.). Можно создать файл robots.txt для сайта онлайн, воспользовавшись генератором файла, например, инструментом сервиса Seolib.
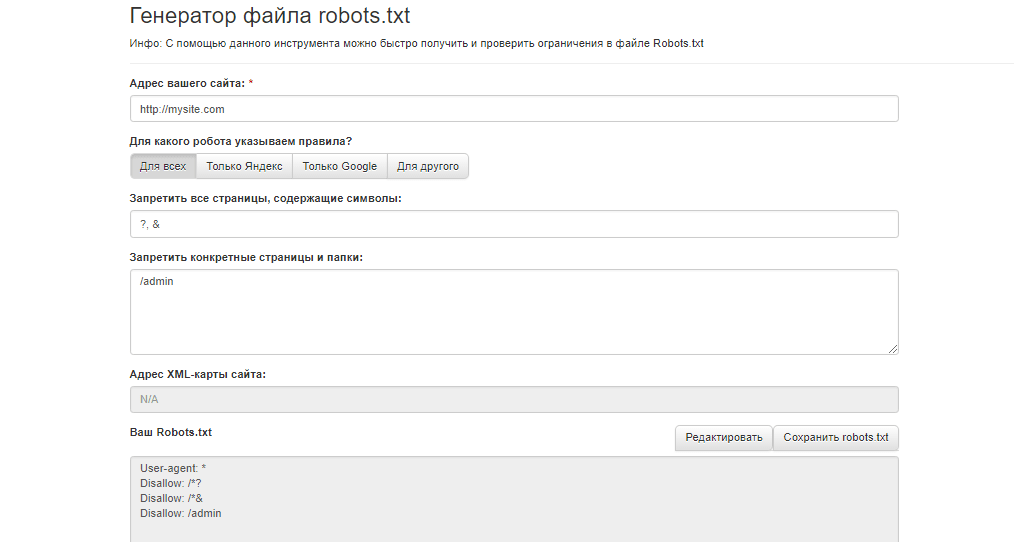
Нужен ли robots.txt?
Прописав правильные инструкции, боты не будут тратить краулинговый бюджет (количество URL, которое может обойти поисковый робот за один обход) на сканирование бесполезных страниц, а проиндексируют только нужные для поиска страницы. В дополнение, не будет перегружаться работа сервера.
Директивы robots.txt
Файл роботс состоит из основных директив: User-agent и Disallow и дополнительных: Allow, Sitemap, Host, Crawl-delay, Clean-param. Ниже мы разберём все правила, для чего они нужны и как их правильно прописать.
User-agent — приветствие с роботом
Существует множество роботов, которые могут сканировать сайт. Наиболее популярными являются боты поисковых систем Google и Яндекса.
В директиве User-agent указывают, к какому роботу обращены инструкции.
Для обращения ко всем роботам достаточно прописать следующую строку в файле:

Для обращения к определённому роботу, например, к Google, нужно прописать в этой строке его имя:
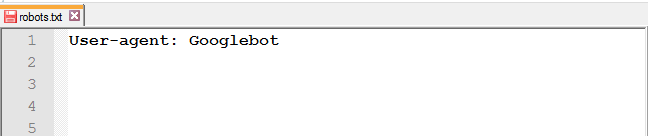
В отличие от Google, дабы не прописывать правила для каждого робота Яндекса, в User-agent можно указать следующее:
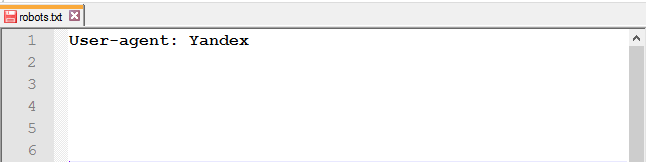
В Рунете принято прописывать инструкции для двух User-agent: для всех и отдельно для Яндекса.
Директивы Disallow и Allow
Чтобы запретить роботу доступ к сайту, каталогу или странице, используйте Disallow.
Как применять правило Disallow в различных ситуациях
Закрыть от индексации весь сайт : используйте слеш (/), чтобы заблокировать доступ ко всему сайту.
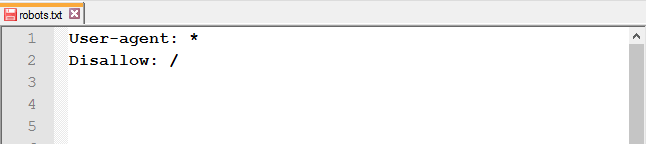
Полностью закрывать доступ роботам стоит на ранних этапах работы с сайтом, чтобы в поисковой выдачи он появился уже готовым.
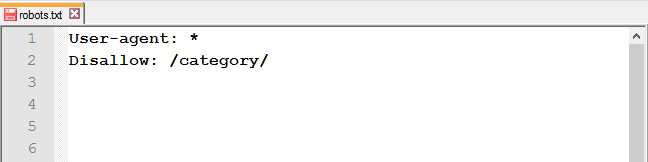
Закрыть доступ к папке и её содержимому : используйте слеш после названия папки.
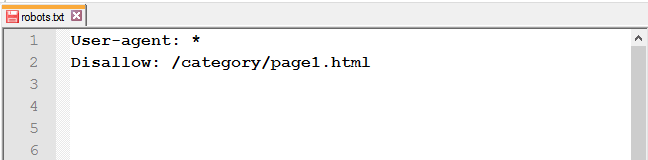
Закрыть определённую страницу или файл : укажите URL без хоста.
Открыть доступ к странице из закрытой папки : после Disallow используйте правило Allow.
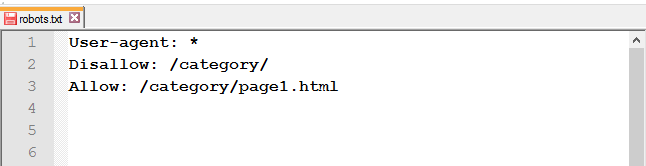
Адрес Sitemap в robots.txt
Если на сайте есть файл Sitemap, укажите в соответствующей директиве адрес к нему. Если же карт сайта несколько, пропишите все.

Это правило учитывается роботами независимо от его месторасположения.
Директива Host для Яндекса
UPD: 20 марта Яндекс официально объявил об отмене директивы Host. Подробнее об этом можно прочитать в блоге Яндекса для вебмастеров.Что теперь делать с директивой Host:
В обоих случаях нужно настроить 301 редирект.
Роботы Яндекса поддерживают robots.txt с расширенными возможностями. Инструкция Host является одной из них. Она указывает главное зеркало сайта.
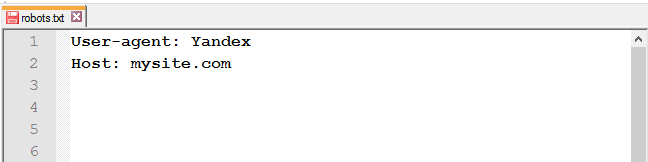
Как и с Sitemap, месторасположение правила не влияет на работу робота, оно может быть указано как в начале файла, так и в конце.
Некорректно прописанная директива Host игнорируется роботом.
Crawl-delay
UPD: ПС Яндекс также отказалась от учёта Crawl-delay. Подробнее в блоге Яндекса для вебмастеров.
Вместо директивы Crawl-delay можно настроить скорость обхода в Яндекс.Вебмастере.
Директива Crawl-delay указывает время, которое роботы должны выдерживать между загрузкой двух страниц. Эта инструкция значительно снизит нагрузку на сервер, если у него есть проблемы с обработкой запросов.
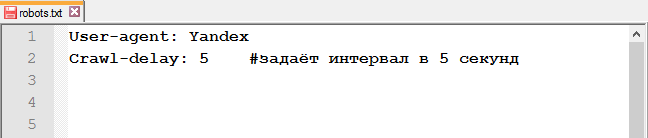
Строка с Crawl-delay должна находиться после всех директив с Allow и Disallow.
Так как Google это правило не учитывает, для гуглбота есть другой метод изменения скорости сканирования.
Clean-param
Для исключения страниц сайта, которые содержат динамические (GET) параметры (например, сортировка товара или идентификаторы сессий), используйте директиву Clean-param.
Например, есть следующие страницы:
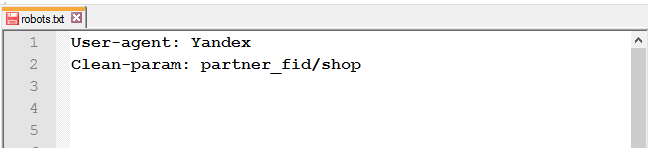
Используя данные из Clean-param, робот не будет перезагружать дублирующуюся информацию.
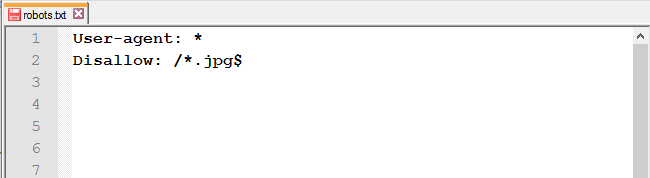
Спецсимвол * (звёздочка) означает любую последовательность символов. То есть, используя звёздочку, вы запретите доступ ко всем URL, содержащим слово «obmanki».

Этот спецсимвол проставляется по умолчанию в конце каждой строки.


Спецсимвол / (слеш) используется в каждой директиве Allow и Disallow. С помощью слеша можно запретить доступ к папке и её содержимому /category/ или ко всем страницам, которые начинаются с /category.

Спецсимвол # (решётка).
Используется для комментариев в файле для себя, пользователей, или других веб-мастеров. Поисковые роботы эту информацию не учитывают. 
Проверка работы файла
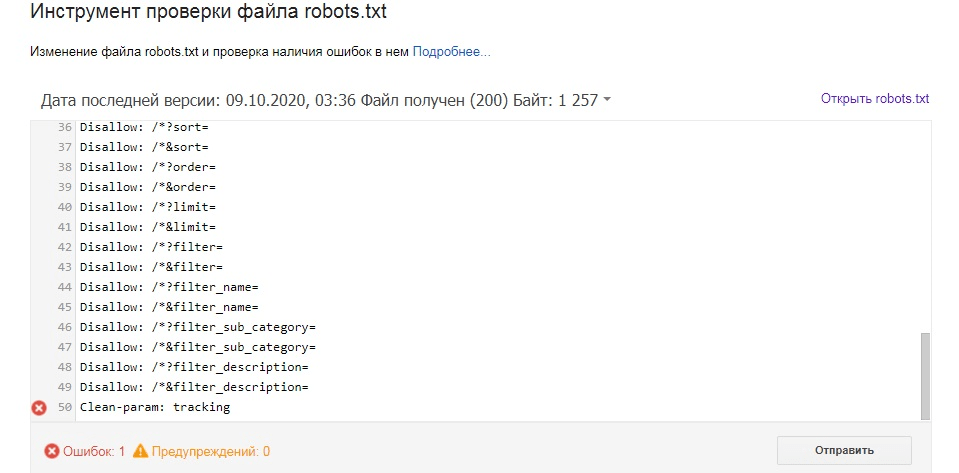
Чтобы проверить файл robots.txt на наличие ошибок, можно воспользоваться инструментами от Google и/или Яндекса.
Как проверить robots.txt в Google Search Console?
Перейдите к инструменту проверки файла. Ошибки и предупреждения будут выделены в содержании роботс.тхт, а общее количество указано под окном редактирования.
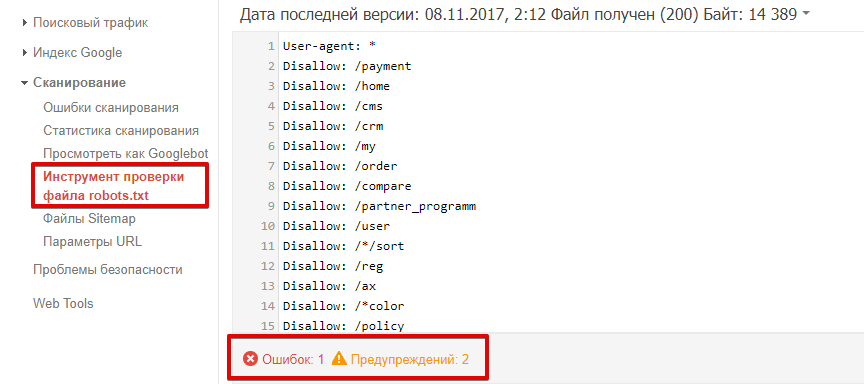
Чтобы проверить, доступна ли страница роботу, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: доступен или недоступен.

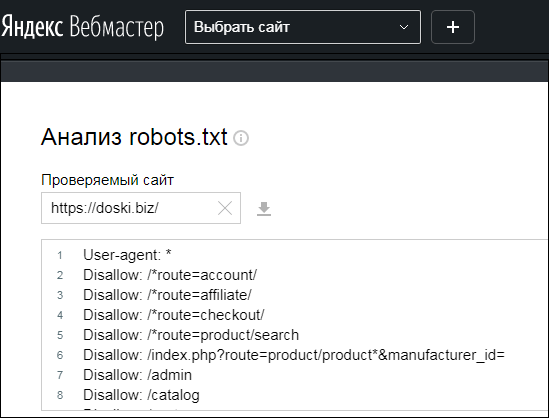
Как проверить robots.txt в Яндекс.Вебмастер?
Для проверки файла нужно перейти в «Инструменты» — «Анализ robots.txt».
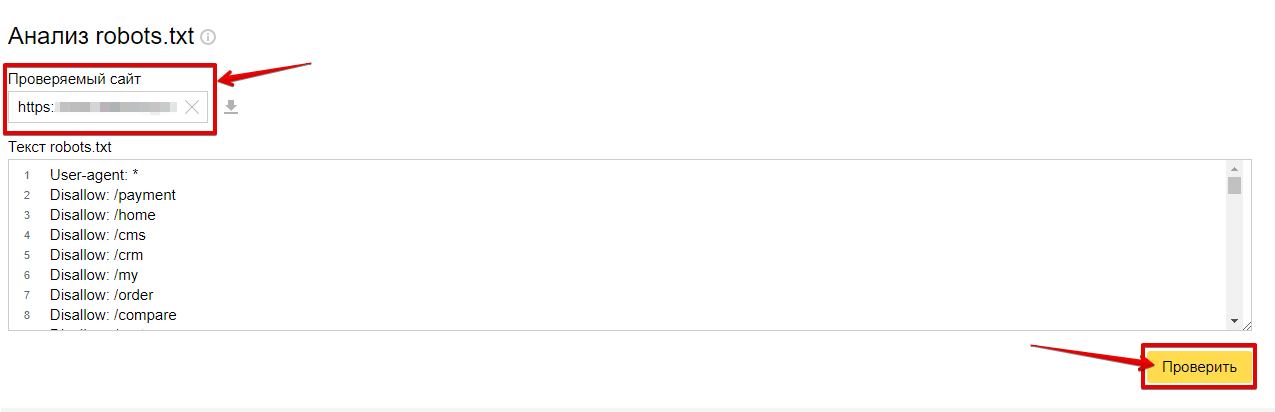
Список ошибок, возникающих при анализе роботс.
Чтобы проверить, разрешён ли доступ к странице, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: знак галочки (разрешён) или будет выведена директива, запрещающая доступ.
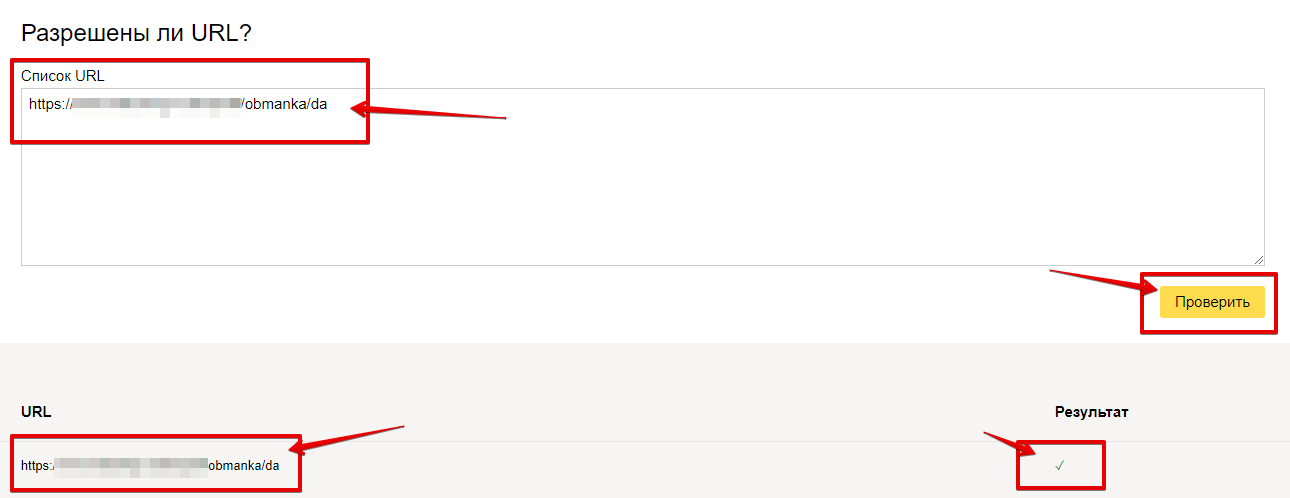
Распространённые ошибки
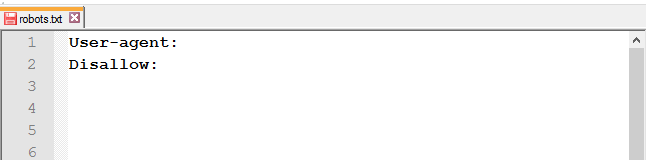

или 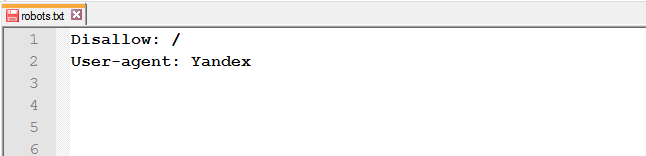
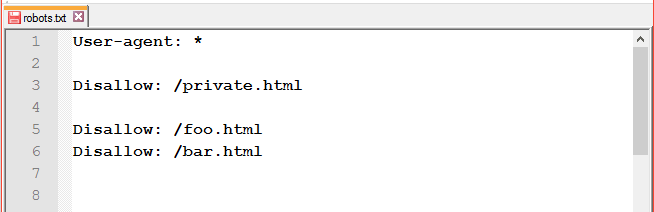
Поисковые системы не рекомендуют закрывать эти файлы от роботов.


Robots.txt для различных CMS
Ниже мы предлагаем рассмотреть часто используемые директивы для различных CMS. Это не конечный вариант файла robots.txt. Этот набор правил редактируется под каждый сайт отдельно и зависит от того, что нужно закрыть, а что — оставить открытым.
Robots.txt для WordPress
Пример файла под Вордпресс:
Robots.txt для Joomla
Пример роботс для Джумла:
Robots.txt для Bitrix
Пример файла для Битрикса:
Заключение
Файл Robots.txt — полезный инструмент в формировании взаимоотношений между поисковыми роботами и вашим сайтом. При правильном использовании он может оказать положительное влияние на ранжирование и сделать сайт более удобным для сканирования. Используйте это руководство, чтобы понять, как работает robots.txt, как он устроен и как его использовать.
P.S. В знак благодарности, что дочитали статью до конца, мы подготовили подборку неожиданных находок в файлах robots.txt.
Площадка для обмена знаниями, учебниками и ГДЗ

Приглашение на работу от известного SEO-сервиса
Ещё одно приглашение, но уже в файле humans.txt
После 2166 запрещающих, направляющих и разрешающих директив, в конце файла можно обнаружить рисуночек
Для чего нужен файл robots.txt? Как его настроить и проверить
Файл robots.txt — это текстовый документ в корневом каталоге сайта с информацией для поисковых роботов о том, какие URL (на которых расположены страницы, файлы, папки, прочее) стоит сканировать, а какие — нет. Наличие этого файла не является обязательным условием для работы ресурса, но в то же время правильное его заполнение лежит в основе SEO.
Решение об использовании robots.txt было принято еще в 1994 году в рамках «Стандарта исключений для роботов». Согласно справке Google, файл предназначен не для запрета показа веб-страниц в результатах поиска, а для ограничения количества запросов роботов к сайту и снижения нагрузки на сервер.
В целом содержимое robots.txt стоит отнести к разряду рекомендаций поисковым ботам, задающих правила сканирования страниц сайта. Чтобы увидеть содержимое robots.txt на любом сайте, нужно добавить к имени домена в браузере /robots.txt.
Для чего используют robots.txt?
К основным функциям документа можно отнести закрытие от сканирования страниц и файлов ресурса в целях рационального расхода краулингового бюджета. Чаще всего закрывают информацию, которая не несет ценности для пользователя и не влияет на позиции сайта в поиске.
| Примечание. Краулинговый бюджет — количество страниц сайта, которое может просканировать поисковый робот. Для его экономии стоит направлять робота только к самому важному содержимому ресурса, закрывая доступ к малополезной информации. |
Какие страницы и файлы закрывают с помощью robots.txt
1. Страницы с персональными данными.
Это могут быть имена и телефоны, которые посетители указывают при регистрации, страницы личного кабинета, номера платежных карт. В целях безопасности доступ к этой информации стоит дополнительно защищать паролем.
2. Вспомогательные страницы, которые появляются только при определенных действиях пользователя.
К ним можно отнести сообщения об успешно оформленном заказе, клиентские формы, страницы авторизации или восстановления пароля.
3. Админпанель и системные файлы.
Внутренние и служебные файлы, с которыми взаимодействует администратор сайта или вебмастер.
4. Страницы поиска и сортировки.
На страницы, которые отображаются по запросу, указанному в окне поиска на сайте, как правило, ставят запрет сканирования. Это же относится к результатам сортировки товаров по цене, рейтингу и другим критериям. Исключением могут быть сайты-агрегаторы.
5. Страницы фильтров.
Результаты, которые отображаются после применения фильтров (размер, цвет, производитель и т.д.), являются отдельными страницами и могут быть расценены как дубли контента. SEO-специалисты, как правило, ограничивают их сканирование, за исключением ситуаций, когда они приносят трафик по брендовым и другим целевым запросам.
6. Файлы определенного формата.
К ним могут относиться фото, видео, PDF-документы, JS-скрипты. С помощью robots.txt можно ограничивать сканирование файлов как по отдельности, так и по определенному расширению.
Как создать и где разместить robots.txt?
Инструменты для настройки robots txt
Также можно использовать генератор robots.txt. Некоторые сайты предоставляют бесплатные инструменты создания на основании заданных вами условий.
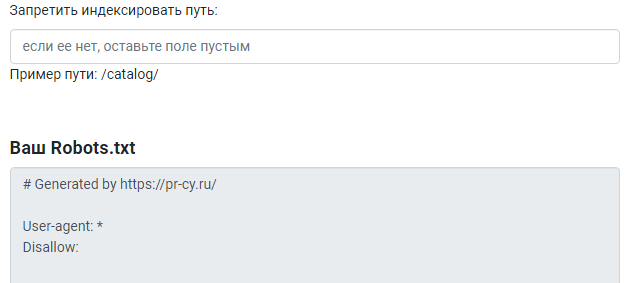
Название и размер документа
Имя файла robots.txt должно выглядеть именно так, без использования заглавных букв. Допустимый размер документа согласно рекомендациям Google и Яндекса — 500 КиБ. При превышении лимита робот может обработать документ частично, воспринять как полный запрет сканирования или, наоборот, пройтись по всему содержимому ресурса.
Где разместить файл
Документ находится в корневом каталоге на хостинге и доступ к нему возможен через FTP. Перед внесением изменений рекомендуется сначала скачать robots.txt в исходном виде.
Синтаксис и директивы robots.txt
Теперь разберем синтаксис robots.txt, состоящий из директив (правил), параметров (страниц, файлов, каталогов) и специальных символов, а также функции, которые они выполняют.
Общие требования к содержимому файла
1. Каждая директива должна начинаться с новой строки и формироваться по принципу: одна строка = одна директива + один параметр.
| Ошибка | User-agent: * Disallow: /folder-1/ Disallow: /folder-2/ | |||||||||||||||||||||||||||||||||||||||||||||||
| Правильно | User-agent: * 2. Названия файлов с использованием кириллицы и других алфавитов, отличных от латинского, следует преобразовать с помощью конвертера Punycode.
3. В синтаксисе параметров необходимо придерживаться соответствующего регистра. Если имя папки начинается с большой буквы, название с маленькой буквы дезориентирует робота. И наоборот.
4. Недопустимо использование пробела в начале строки, кавычек для директив или точек с запятой после них.
|