Конвертер текста в юникод
Конвертер для перевода любого текста (не только кириллицы) в Юникод. Набирайте текст — он будет автоматически преобразован по мере его набора. Либо вставьте текст из буфера и нажмите кнопку. Ограничение на длину текста — 3000 символов.
Что такое Юникод?
Юникод — это стандарт универсальной кодировки символов, который используется для поддержки символов, не входящих в набор ASCII. Изначально Интернет был создан на базе кодировки ASCII, которая содержит символы английского алфавита и состоит всего из 128 символов.
Юникод обеспечивает поддержку всех языков мира и их уникальных наборов символов — Юникод может поддерживать более 1 миллиона символов!
Причина в том, что в Юникоде для представления символа может использоваться больше бит (от английского binary digit — двоичное число), которые представляют собой единицы информации в компьютерах. Символы ASCII требуют только 7 бит, а Юникод может использовать 16 бит. Это необходимо, потому что для таких языков, как китайский, арабский и русский, требуется больше бит.
Кодовое пространство
Кодовое пространство разбито на 17 плоскостей по 216 (65536) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей. Плоскости 16 и 17 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида « U+xxxx » (для кодов 0…FFFF) или « U+xxxxx » (для кодов 10000…FFFFF) или « U+xxxxxx » (для кодов 100000…10FFFF),
где xxx — шестнадцатеричные цифры.
Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Состоит стандарт из двух главных разделов:
Универсальным набором символов задаётся однозначная пропорциональность кодам символов. Коды в этом случае представляют собой элементы кодовой сферы, являющиеся неотрицательными целыми числами. Функция семейства кодировок – определение машинного представления последовательности UCS-кодов.
Под кириллицу определены следующие области символов с кодами:
Юникод для чайников

Сам я не очень люблю заголовки вроде «Покемоны в собственном соку для чайников\кастрюль\сковородок», но это кажется именно тот случай — говорить будем о базовых вещах, работа с которыми довольно часто приводить к купе набитых шишек и уйме потерянного времени вокруг вопроса — «Почему же оно не работает?». Если вы до сих пор боитесь и\или не понимаете Юникода — прошу под кат.
Зачем?
Главный вопрос новичка, который встречается с впечатляющим количеством кодировок и на первый взгляд запутанными механизмами работы с ними (например, в Python 2.x). Краткий ответ — потому что так сложилось 🙂
Кодировкой, кто не знает, называют способ представления в памяти компьютера (читай — в нулях-единицах\числах) цифр, буков и всех остальных знаков. Например, пробел представляется как 0b100000 (в двоичной), 32 (в десятичной) или 0x20 (в шестнадцатеричной системе счисления).
Так вот, когда-то памяти было совсем немного и всем компьютерам было достаточно 7 бит для представления всех нужных символов (цифры, строчный\прописной латинский алфавит, куча знаков и так называемые управляемые символы — все возможные 127 номеров были кому-то отданы). Кодировка в это время была одна — ASCII. Шло время, все были счастливы, а кто не был счастлив (читай — кому не хватало знака «©» или родной буквы «щ») — использовали оставшиеся 128 знаков на свое усмотрение, то есть создавали новые кодировки. Так появились и ISO-8859-1, и наши (то есть кириличные) cp1251 и KOI8. Вместе с ними появилась и проблема интерпретации байтов типа 0b1******* (то есть символов\чисел от 128 и до 255) — например, 0b11011111 в кодировке cp1251 это наша родная «Я», в тоже время в кодировке ISO-8859-1 это греческая немецкая Eszett (подсказывает Moonrise) «ß». Ожидаемо, сетевая коммуникация и просто обмен файлами между разными компьютерами превратились в чёрт-знает-что, несмотря на то, что заголовки типа ‘Content-Encoding’ в HTTP протоколе, email-письмах и HTML-страницах немного спасали ситуацию.
В этот момент собрались светлые умы и предложили новый стандарт — Unicode. Это именно стандарт, а не кодировка — сам по себе Юникод не определяет, как символы будут сохранятся на жестком диске или передаваться по сети. Он лишь определяет связь между символом и некоторым числом, а формат, согласно с которым эти числа будут превращаться в байты, определяется Юникод-кодировками (например, UTF-8 или UTF-16). На данный момент в Юникод-стандарте есть немного более 100 тысяч символов, тогда как UTF-16 позволяет поддерживать более одного миллиона (UTF-8 — и того больше).
Ближе к делу!
Естественно, есть поддержка Юникода и в Пайтоне. Но, к сожалению, только в Python 3 все строки стали юникодом, и новичкам приходиться убиваться об ошибки типа:
Давайте разберемся, но по порядку.
Зачем кто-то использует Юникод?
Почему мой любимый html-парсер возвращает Юникод? Пусть возвращает обычную строку, а я там уже с ней разберусь! Верно? Не совсем. Хотя каждый из существующих в Юникоде символов и можно (наверное) представить в некоторой однобайтовой кодировке (ISO-8859-1, cp1251 и другие называют однобайтовыми, поскольку любой символ они кодируют ровно в один байт), но что делать если в строке должны быть символы с разных кодировок? Присваивать отдельную кодировку каждому символу? Нет, конечно, надо использовать Юникод.
Зачем нам новый тип «unicode»?
Вот мы и добрались до самого интересного. Что такое строка в Python 2.x? Это просто байты. Просто бинарные данные, которые могут быть чем-угодно. На самом деле, когда мы пишем что-нибудь вроде:интерпретатор не создает переменную, которая содержит первые четыре буквы латинского алфавита, но только последовательность с четырёх байт, и латинские буквы здесь используются исключительно для обозначения именно этого значения байта. То есть ‘a’ здесь просто синоним для написания ‘\x61’, и ни чуточку больше. Например:
И ответ на вопрос — зачем нам «unicode» уже более очевиден — нужен тип, который будет представятся символами, а не байтами.
Хорошо, я понял чем есть строка. Тогда что такое Юникод в Пайтоне?
«type unicode» — это прежде всего абстракция, которая реализует идею Юникода (набор символов и связанных с ними чисел). Объект типа «unicode» — это уже не последовательность байт, но последовательность собственно символов без какого либо представления о том, как эти символы эффективно сохранить в памяти компьютера. Если хотите — это более высокой уровень абстракции, чем байтовый строки (именно так в Python 3 называют обычные строки, которые используются в Python 2.6).
Как пользоваться Юникодом?
Как из юникод-строки получить обычную? Закодировать её:
Алгоритм кодирования естественно обратный приведенному выше.
Не кодируется 🙁
Разберем примеры с начала статьи. Как работает конкатенация строки и юникод-строки? Простая строка должна быть превращена в юникод-строку, и поскольку интерпретатор не знает кодировки, от использует кодировку по умолчанию — ascii. Если этой кодировке не удастся декодировать строку, получим некрасивую ошибку. В таком случае нам нужно самим привести строку к юникод-строке, используя правильную кодировку:
«UnicodeDecodeError» обычно есть свидетельством того, что нужно декодировать строку в юникод, используя правильную кодировку.
Теперь использование «str» и юникод-строк. Не используйте «str» и юникод строки 🙂 В «str» нет возможности указать кодировку, соответственно кодировка по умолчанию будет использоваться всегда и любые символы > 128 будут приводить к ошибке. Используйте метод «encode»:
«UnicodeEncodeError» — знак того, что нам нужно указать правильную кодировку во время превращения юникод-строки в обычную (или использовать второй параметр ‘ignore’\’replace’\’xmlcharrefreplace’ в методе «encode»).
Хочу ещё!
Хорошо, используем бабу-ягу из примера выше ещё раз:
Есть ещё способ использования «u»» для представления, например, кириллицы, и при этом не указывать кодировку или нечитабельные юникод-поинты (то есть «u’\u1234’»). Способ не совсем удобный, но интересный — использовать unicode entity codes:
Ну и вроде всё. Основные советы — не путать «encode»\«decode» и понимать различия между байтами и символами.
Python 3
Здесь без кода, ибо опыта нет. Свидетели утверждают, что там всё значительно проще и веселее. Кто возьмется на кошках продемонстрировать различия между здесь (Python 2.x) и там (Python 3.x) — респект и уважуха.
Полезно
Раз уж мы о кодировках, порекомендую ресурс, который время-от-времени помогает побороть кракозябры — http://2cyr.com/decode/?lang=ru.
Unicode HOWTO — официальный документ о том где, как и зачем Юникод в Python 2.x.
Спасибо за внимание. Буду благодарен за замечания в приват.
Юникод: необходимый практический минимум для каждого разработчика
Юникод — это очень большой и сложный мир, ведь стандарт позволяет ни много ни мало представлять и работать в компьютере со всеми основными письменностями мира. Некоторые системы письма существуют уже более тысячи лет, причём многие из них развивались почти независимо друг от друга в разных уголках мира. Люди так много всего придумали и оно зачастую настолько непохоже друг на друга, что объединить всё это в единый стандарт было крайне непростой и амбициозной задачей.
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Зачем понадобился Юникод?
До появления Юникода, почти повсеместно использовались однобайтные кодировки, в которых граница между самими символами, их представлением в памяти компьютера и отображением на экране была довольно условной. Если вы работали с тем или иным национальным языком, то в вашей системе были установлены соответствующие шрифты-кодировки, которые позволяли отрисовывать байты с диска на экране таким образом, чтобы они представляли смысл для пользователя.
Если вы распечатывали на принтере текстовый файл и на бумажной странице видели набор непонятных кракозябр, это означало, что в печатающее устройство не загружены соответствующие шрифты и оно интерпретирует байты не так, как вам бы этого хотелось.
У такого подхода в целом и однобайтовых кодировок в частности был ряд существенных недостатков:
Основные принципы Юникода
Все мы прекрасно понимаем, что компьютер ни о каких идеальных сущностях знать не знает, а оперирует битами и байтами. Но компьютерные системы пока создают люди, а не машины, и для нас с вами иногда бывает удобнее оперировать умозрительными концепциями, а затем уже переходить от абстрактного к конкретному.
Важно! Одним из центральных принципов в философии Юникода является чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
Вводится понятие абстрактного юникод-символа, существующего исключительно в виде умозрительной концепции и договорённости между людьми, закреплённой стандартом. Каждому юникод-символу поставлено в соответствие неотрицательное целое число, именуемое его кодовой позицией (code point).
Так, например, юникод-символ U+041F — это заглавная кириллическая буква П. Существует несколько возможностей представления данного символа в памяти компьютера, ровно как и несколько тысяч способов отображения его на экране монитора. Но при этом П, оно и в Африке будет П или U+041F.
Это хорошо нам знакомая инкапсуляция или отделение интерфейса от реализации — концепция, отлично зарекомендовавшая себя в программировании.
Получается, что руководствуясь стандартом, любой текст можно закодировать в виде последовательности юникод-символов
записать на листочке, упаковать в конверт и переслать в любой конец Земли. Если там знают о существовании Юникода, то текст будет воспринят ими ровно так же, как и нами с вами. У них не будет ни малейших сомнений, что предпоследний символ — это именно кириллическая строчная е (U+0435), а не скажем латинская маленькая e (U+0065). Обратите внимание, что мы ни слова не сказали о байтовом представлении.
Хотя юникод-символы и называются символами, они далеко не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу. (Подробнее смотри под спойлером.)
Что такое символ, чем отличается графемный кластер (читай: воспринимаемое как единое целое изображение символа) от юникод-символа и от кодового кванта мы расскажем в следующий раз.
Кодовое пространство Юникода
Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF. Из них к девятой версии стандарта значения присвоены лишь 128 237. Часть пространства зарезервирована для частного использования и консорциум Юникода обещает никогда не присваивать значения позициям из этих специальный областей.
Ради удобства всё пространство поделено на 17 плоскостей (сейчас задействовано шесть их них). До недавнего времени было принято говорить, что скорее всего вам придётся столкнуться только с базовой многоязыковой плоскостью (Basic Multilingual Plane, BMP), включающей в себя юникод-символы от U+0000 до U+FFFF. (Забегая немного вперёд: символы из BMP представляются в UTF-16 двумя байтами, а не четырьмя). В 2016 году этот тезис уже вызывает сомнения. Так, например, популярные символы Эмодзи вполне могут встретиться в пользовательском сообщении и нужно уметь их корректно обрабатывать.
Кодировки
Если мы хотим переслать текст через Интернет, то нам потребуется закодировать последовательность юникод-символов в виде последовательности байтов.
Стандарт Юникода включает в себя описание ряда юникод-кодировок, например UTF-8 и UTF-16BE/UTF-16LE, которые позволяют кодировать всё пространство кодовых позиций. Конвертация между этими кодировками может свободно осуществляться без потерь информации.
Также никто не отменял однобайтные кодировки, но они позволяют закодировать свой индивидуальный и очень узкий кусочек юникод-спектра — 256 или менее кодовых позиций. Для таких кодировок существуют и доступны всем желающим таблицы, где каждому значению единственного байта сопоставлен юникод-символ (см. например CP1251.TXT). Несмотря на ограничения, однобайтные кодировки оказываются весьма практичными, если речь идёт о работе с большим массивом моноязыковой текстовой информации.
Из юникод-кодировок самой распространённой в Интернете является UTF-8 (она завоевала пальму первенства в 2008 году), главным образом благодаря её экономичности и прозрачной совместимости с семибитной ASCII. Латинские и служебные символы, основные знаки препинания и цифры — т.е. все символы семибитной ASCII — кодируются в UTF-8 одним байтом, тем же, что и в ASCII. Символы многих основных письменностей, не считая некоторых более редких иероглифических знаков, представлены в ней двумя или тремя байтами. Самая большая из определённых стандартом кодовых позиций — 10FFFF — кодируется четырьмя байтами.
Обратите внимание, что UTF-8 — это кодировка с переменной длиной кода. Каждый юникод-символ в ней представляется последовательностью кодовых квантов с минимальной длиной в один квант. Число 8 означает битовую длину кодового кванта (code unit) — 8 бит. Для семейства кодировок UTF-16 размер кодового кванта составляет, соответственно, 16 бит. Для UTF-32 — 32 бита.
Если вы пересылаете по сети HTML-страницу с кириллическим текстом, то UTF-8 может дать весьма ощутимый выигрыш, т.к. вся разметка, а также JavaScript и CSS блоки будут эффективно кодироваться одним байтом. К примеру главная страница Хабра в UTF-8 занимает 139Кб, а в UTF-16 уже 256Кб. Для сравнения, если использовать win-1251 с потерей возможности сохранять некоторые символы, то размер, по сравнению с UTF-8, сократится всего на 11Кб до 128Кб.
Для хранения строковой информации в приложениях часто используются 16-битные юникод-кодировки в силу их простоты, а так же того факта, что символы основных мировых систем письма кодируются одним шестнадцатибитовым квантом. Так, например, Java для внутреннего представления строк успешно применяет UTF-16. Операционная система Windows внутри себя также использует UTF-16.
В любом случае, пока мы остаёмся в пространстве Юникода, не так уж и важно, как хранится строковая информация в рамках отдельного приложения. Если внутренний формат хранения позволяет корректно кодировать все миллион с лишним кодовых позиций и на границе приложения, например при чтении из файла или копировании в буфер обмена, не происходит потерь информации, то всё хорошо.
Для корректной интерпретации текста, прочитанного с диска или из сетевого сокета, необходимо сначала определить его кодировку. Это делается либо с использованием метаинформации, предоставленной пользователем, записанной в тексте или рядом с ним, либо определяется эвристически.
В сухом остатке
Информации много и имеет смысл привести краткую выжимку всего, что было написано выше:
Краткое замечание про кодирование
С термином кодирование может произойти некоторая путаница. В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set). Второй раз последовательность юникод-символов преобразуется в строку байтов и этот процесс также называется кодирование.
В англоязычной терминологии существуют два разных глагола to code и to encode, но даже носители языка зачастую в них путаются. К тому же термин набор символов (character set или charset) используется в качестве синонима к термину кодированный набор символов (coded character set).
Всё это мы говорим к тому, что имеет смысл обращать внимание на контекст и различать ситуации, когда речь идёт о кодовой позиции абстрактного юникод-символа и когда речь идёт о его байтовом представлении.
FoxTools v.2.0
Привет, Гость! Ваш IP: 5.188.119.3
Таблица символов Юникода
DEC: 
HEX:
Html:
Что такое Юникод?
В отличие от ASCII, один символ кодируется двумя байтами, что позволяет использовать 65 536 символов, против 256.
Символы Юникода разделены на секции. Первые 128 символов повторяют таблицу ASCII.
Как пользоваться таблицей?
Символы представлены по 16 штук на строке. Сверху вы можете видеть шестнадцатеричное число от 0 до 16. Слева аналогичные числа в шестнадцатеричном виде от 0 до FFF.
Соединив число слева с числом сверху, можно узнать код символа. Например: английская буква F расположена на строке 004, в столбике 6: 004 + 6 = код символа 0046.
Впрочем, вы можете просто навести курсор на конкретный символ в таблице, чтобы узнать код символа. Либо нажать на символ, чтобы скопировать его, или его код в одном из форматов.
В поисковое поле можно ввести ключевые слова поиска, например: стрелки, солнце, сердце. Либо можно указать код символа в любом формате, например: 1123, 04BC, چ. Или сам символ, если требуется узнать код символа.
Поиск по ключевым словам в данный момент находится на стадии разработки, поэтому может не выдавать результатов. Но многие популярные символы уже можно найти.
К сожалению, в данный момент таблица не работает на мобильных устройствах.
В Application Programming Interface этот сервис не реализован. В популярных языках программирования можно легко работать с символами Юникода. Если у вас возникнут какие-либо вопросы, обращайтесь на форум для программистов.
Сайт построен на HTML5
Для корректной работы данного сайта требуется HTML5.
Пожалуйста, воспользуйтесь браузером, который поддерживает HTML5. Многие современные браузеры поддерживают HTML5. Например:
Вставка символов и знаков на основе латинского алфавита в кодировке ASCII или Юникод
С помощью кодировок символов ASCII и Юникода можно хранить данные на компьютере и обмениваться ими с другими компьютерами и программами. Ниже перечислены часто используемые латинские символы ASCII и Юникода. Наборы символов Юникода, отличные от латинских, можно посмотреть в соответствующих таблицах, упорядоченных по наборам.
В этой статье
Вставка символа ASCII или Юникода в документ
Если вам нужно ввести только несколько специальных знаков или символов, можно использовать таблицу символов или сочетания клавиш. Список символов ASCII см. в следующих таблицах или статье Вставка букв национальных алфавитов с помощью сочетаний клавиш.
Многие языки содержат символы, которые не удалось сжатить, в 256-символьный набор extended ACSII. Таким образом, существуют варианты ASCII и Юникода, которые должны включать региональные символы и символы, и см. таблицы кодов символов Юникода по сценариям.
Если у вас возникают проблемы с вводом кода необходимого символа, попробуйте использовать таблицу символов.
Вставка символов ASCII
Чтобы вставить символ ASCII, нажмите и удерживайте клавишу ALT, вводя код символа. Например, чтобы вставить символ градуса (º), нажмите и удерживайте клавишу ALT, затем введите 0176 на цифровой клавиатуре.
Для ввода чисел используйте цифровую клавиатуру, а не цифры на основной клавиатуре. Если на цифровой клавиатуре необходимо ввести цифры, убедитесь, что включен индикатор NUM LOCK.
Вставка символов Юникода
Чтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Юникода см. в таблицах символов Юникода, упорядоченных по наборам.
Важно: Некоторые программы Microsoft Office, например PowerPoint и InfoPath, не поддерживают преобразование кодов Юникода в символы. Если вам необходимо вставить символ Юникода в одной из таких программ, используйте таблицу символов.
Если после нажатия клавиш ALT+X отображается неправильный символ Юникода, выберите правильный код, а затем снова нажмите ALT+X.
Кроме того, перед кодом следует ввести «U+». Например, если ввести «1U+B5» и нажать клавиши ALT+X, отобразится текст «1µ», а если ввести «1B5» и нажать клавиши ALT+X, отобразится символ «Ƶ».
Использование таблицы символов
Таблица символов — это программа, встроенная в Microsoft Windows, которая позволяет просматривать символы, доступные для выбранного шрифта.
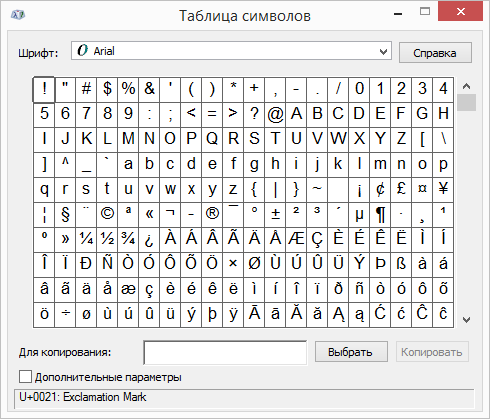
С помощью таблицы символов можно копировать отдельные символы или группу символов в буфер обмена и вставлять их в любую программу, поддерживающую отображение этих символов. Открытие таблицы символов
В Windows 10 Введите слово «символ» в поле поиска на панели задач и выберите таблицу символов в результатах поиска.
В Windows 8 Введите слово «символ» на начальном экране и выберите таблицу символов в результатах поиска.
В Windows 7: Нажмите кнопку Пуск, а затем последовательно выберите команды Программы, Стандартные, Служебные и Таблица знаков.
Знаки группются по шрифтам. Щелкните список шрифтов, чтобы выбрать набор символов. Чтобы выбрать символ, щелкните его, нажмите кнопку «Выбрать», щелкните в документе правую кнопку мыши в том месте, где он должен быть, а затем выберите «Вировать».


