Проверяем все страницы сайта на PR
Мой способ проверки PR
Чтобы массово проверить PR всех внутренних страниц, понадобиться две программы. Первая — которая получит все url страниц сайта. Вторая — позволяющая массово проверять PR страниц.
Парсим страницы сайта
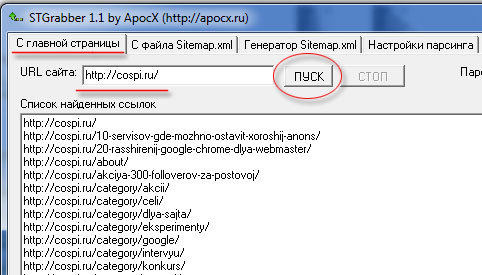
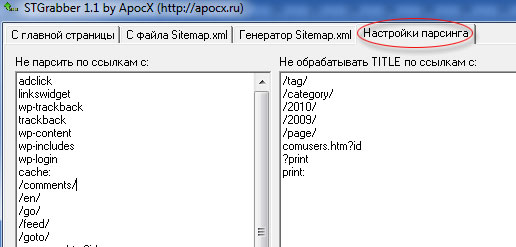
Ждём когда закончит работу программа и копируем список найденных ссылок в текстовый файл, который нам пригодиться для работу в другой программе. Я использую именно эту программу, потому, что у неё есть настройки парсинга (изъятия данных):
Проверяем на PR
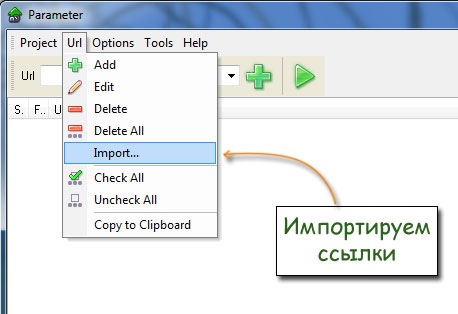
Для этого программу PaRaMeter, импортируем в неё ссылки сайта, которые мы сохранили в текстовом файлике:
И запускаем проверку. Для наглядности я проверил 1500 страниц блога Димка:
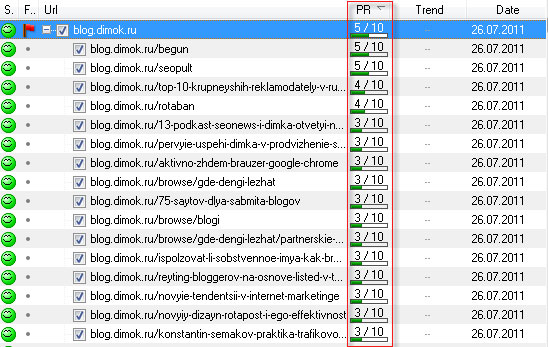
На проверку 1.5 тысячи страниц понадобилось минуты 2-3 примерно. После того, когда программа закончит свою работу, нажимаем кнопочку PR и в таблице все значения от сортируются по убыванию, чтобы удобно было анализировать список. Все обработанные данные можно экспортировать в Excel, для последующего использования. На этом всё, спасибо за внимание.
UPDATE 8.11.2011
Программа PaRaMeter уже не определяет PR, пользуйтесь сервисом, который я описал в статье — Проверка всех страниц сайта на Page Rank.
Список страниц сайта
Использование
Обычно, для получения всех страниц сайта достаточно просто ввести любую его страницу в поле «Сайт» и нажать на кнопку «Получить страницы сайта».
Если по каким-то причинам не удалось получить страницы, то прочитайте следующий раздел.
Как работает сервис
В большинстве случаев, у каждого сайта есть файл, в котором перечислены все его внутрненние ссылки и называется Sitemap. Как правило, он находится по адресу [сайт]/sitemap.xml (напр.: vivazzi.pro/sitemap.xml). По этому файлу данный сервис извлекает все внутренние ссылки сайта.
В редких случаях, разработчики сайта могут использовать другое месторасположение файла Sitemap. В этом случае сервис попытается найти файл, указанный в robots.txt. Если robots.txt у сайта не доступен или sitemap-файл, указанный в robots.txt, не существует, то сервис не сможет выдать страницы сайта, так как сервис не осуществляет автоматический обход страниц по ссылкам сайта, как это делают поисковые системы (Google, Yandex и т. д.) или программы-пауки (majento, xenu и т. д.).
Если вы не получили страницы сайта, то попробуйте использовать различные программы-пауки, но, возможно, обычному пользователю будет трудно разобраться.
Ещё есть способ получить все ссылки сайта через поисковую систему Google или Yandex, вписав в адресную строку запрос:
Например: site:vivazzi.pro (Более подробно ознакомится с командой site: вы можете на странице Исключить поддомены командой site: в google)
Но этот способ имеет недостаток: показываются только те страницы, которые вошли в поиск, а остальные страницы будут проигнорированы, если они не вошли в поиск (не проиндексировались) по каким-то причинам.
Как получить список страниц сайта: 4 способа с плюсами и минусами

Регулярный технический анализ сайта – это единственный путь к прибыли и постоянному росту. Для его проведения можно использовать самые разные инструменты от краулинг-сервисов до стандартизованных операторов типа site. Иногда для дополнительной проверки, контроля результатов аудита или других целей в рамках технического анализа веб-мастеру требуется полный список страниц ресурса. Как получить список страниц сайт? Получить их можно разными способами, но в каждом случае есть свои оговорки.
Так, варианты «формирования» перечня URL для конкретного сайта:
Работа с XML-картами
При проверке маленьких сайтов (до 100 тысяч страниц) это самый удобный способ получить список адресов, в том числе для написания кода на поиск уязвимостей. Но при аудите крупных ресурсов в выборке отразятся далеко не все страницы. Причин расхождений может быть много – неправильная настройка индексации, программные ошибки (баги), когда сайт сам формирует десятки дополнительных URL, так называемые мусорные страницы, которые не закрыты через robots.txt.
Практика показывает, что в полученном перечне может недоставать до 80% страниц. Если использовать выборку с таким дефицитом информации как основу для внесения исправлений на сайт, можно потерять массу полезной информации и получить совершенно неверные приоритетные ошибки: хвататься за скорость загрузки, тогда как основной проблемой является индексация, или наоборот. У технического анализа части страниц погрешность может оказаться очень большой.
Консоль Яндекса
Выборка из поисковой консоли дает более высокую вероятность полноты итогового списка адресов страниц. Это при условии, что сайт технически выполнен без откровенных ошибок. Если ошибки есть, и портал большой, то риск получить неполный список растет.
Правда, не так сильно, как в других случаях. Потому при необходимости провести анализ быстро (или получить список URL для других целей в режиме здесь и сейчас) этот вариант можно рассматривать как оптимальный.
Поверхностное сканирование
При поверхностном сканировании каждый URL анализируется на предмет присутствия на нем других адресов. Такой вариант дает самые высокие шансы получить полный перечень адресов. Но и по трудозатратам он первый. Рутинной работы с ним много. Надо:
Если ни на одном из этапов не допустить ошибок, результат будет точным. Но когда он будет?
Ручная загрузка списка страниц сайта
Если ресурс создан меньше месяца назад (и ему де-факто не нужен список страниц, потому что такие молодые сайты можно проверять и без него), ручная загрузка подходит. В остальных случаях (особенно после года активного развития) веб-мастер уже не может быть на 100% уверенным, что у него полный список страниц.
Чтобы проверить себя, можно посмотреть файлы (логи) роботов, сформированные по запросу. С большой вероятностью там уже будут десятки URL неизвестной природы.
Как найти поддомены за считанные минуты?
Поиск поддоменов — неотъемлемая часть подготовки ко взлому, а благодаря некоторым инструментам противостояние этим действиям стало намного проще.
Незащищенные поддомены подвергают вашу деятельность серьезной опасности, а в последнее время произошел целый ряд инцидентов, при которых взломщики воспользовались поддоменами для обхода защиты.
В случае последнего из череды инцидентов весь код сайта Vine можно было загрузить с незащищенного поддомена.
Если вы владелец сайта или изучаете вопросы информационной безопасности, вы можете воспользоваться следующими инструментами чтобы найти поддомены любого домена.

От переводчика:
Надеюсь, что данные инструменты помогут Вам сохранить информацию на ваших виртуальных и выделенных серверах.
Вы получите неплохой обзор сведений о домене.
2. Pentest-Tools
С помощью Pentest-Tools при поиске поддомена можно воспользоваться несколькими методами, например: передача зоны DNS, перебор DNS на основе списка слов или использование поисковой системы.
Результаты поиска можно сохранить в формате PDF.
3. DNS Dumpster
DNS Dumpster — это инструмент для поиска информации о домене и хосте. Авторы проекта — HackerTarget.com.
Вы сможете найти сведения не только о поддомене, но и о DNS сервере, MX и TXT записях, а также получить графическое представление информации о вашем домене.
4. Sublist3r
Sublist3r — это инструмент на языке Python для обнаружения поддоменов с помощью поисковых систем. На сегодняшний день Sublist3r поддерживает Google, Yahoo, Bing, Baidu, Ask, Netcraft, Virustotal, ThreatCrowd, DNSdumpster and PassiveDNS.
Sublist3r поддерживает только Python версии 2.7 и зависит от нескольких библиотек.
Вы можете использовать этот инструмент в Windows, CentOS, RedHat, Ubuntu, Debian и любой другой ОС на базе UNIX. Ниже приводится пример для CentOS.
Распакуйте скачанный файл:
Теперь все готово для обнаружения поддоменов с помощью следующей команды:
Как видите, инструмент обнаружил мои поддомены.
5. Netcraft
Netcraft располагает обширной базой данных о доменах и ее не стоит обходить стороной при поиске открытой информации о поддоменах.
Результат поиска будет содержать всю информацию о домене и поддоменах, в том числе дату первого просмотра, диапазоне адресов и информацию об операционной системе. Если вам необходимо получить больше информации о сайте, просто откройте отчет о сайте и вам будет предоставлена уйма информации о технологиях, рейтинге и т.д.
6. CloudPiercer
CloudPiercer может иногда оказаться полезным при поиске информации о том, существует ли поддомен вашего домена. Кстати, CloudPiercer — это потрясающий и простой способ узнать защищен ли фактический IP-адрес вашего сайта.Открытая информация об IP-адресе делает ваш сайт уязвимым для DDoS-атак.
7. Detectify
Detectify осуществляет поиск поддоменов по предопределенному списку из нескольких сотен слов, но только в случае, если вы являетесь собственником домена. Тем не менее, если вы являетесь зарегистрированным пользователем Detectify, вы сможете включить функцию обнаружения поддоменов в разделе overview в настройках.
8. SubBrute
SubBrute — это один из самых популярных и точных инструментов перечисления поддоменов. Проект разработан сообществом и использует открытый определитель имен в качестве прокси, так что SubBrute не отправляет трафик на целевой DNS-сервер.
Это не онлайн-инструмент, так что вам придется установить его на компьютер. SubBrute можно использовать на Windows или UNIX системах. Программу установить очень легко. Ниже пример для CentOS/Linux.
Будет создана новая папка “subbrute-master”. Зайдите в папку и выполните subbrute.py с необходимым доменом.
Операция займет несколько секунд и отобразятся найденные поддомены.
9. Knock
Knock — еще один инструмент на языке Python для обнаружения поддоменов. Он протестирован для Python 2.7.6. Knock находит поддомены целевого домена по списку слов.
После установки вы можете производить поиск поддоменов следующим образом:
10. DNSRecon для Kali Linux
Kali Linux — это отличная платформа для оценки информационной безопасности и на ней можно использовать DNSRecon без дополнительной установки каких-либо инструментов.
DNSRecon проверяет все NS-записи на предмет смены зон, общие записи DNS, обработку шаблонов, PTR-записи и т.д.
Чтобы воспользоваться DNSRecon, просто выполните следующую команду
Надеюсь, что с помощью приведенных выше инструментов вы сможете обнаружить поддомены целевого домена в рамках вашей работы по оценке информационной безопасности. Сообщите мне, какой вам понравился больше всего.
Как найти все страницы сайта и не потратить на это вечность
Уследить за всеми страницами сайта сложно, особенно если сайт большой. Но иногда без полного списка страниц не обойтись. Например, если вы хотите создать xml карту сайта, удалить лишние страницы или настроить внутреннюю перелинковку.
С полным списком страниц вы сможете очистить сайт от мусора, исправить технические ошибки на страницах и улучшить ранжирование. Возникает логичный вопрос: как собрать такой список максимально быстро и просто.
Легче всего выгрузить все страницы из одного инструмента, но тогда ваш список может оказаться неполным. Чтобы собрать абсолютно все страницы, в том числе закрытые от поисковых роботов и страницы с техническими ошибками, придется потрудиться.
Почему для сбора данных одного инструмента мало
Собирать данные мы будем из трех инструментов:
Сравнив все данные мы получим полный список страниц вашего сайта.
Проиндексированные URL-ы мы найдем еще на первом этапе. Но нам нужны не только они. У многих сайтов найдутся страницы, на которые не ведет ни одна внутренняя ссылка. Их называют страницами-сиротами.
Почему страницы оказываются «в изоляции»? Причины могут быть разные, к примеру:
С помощью разных инструментов мы найдем абсолютно все страницы. Но давайте по порядку. Для начала выгрузим список всех проиндексированных и корректно работающих страниц.
Ищем открытые для краулеров страницы в SE Ranking
Экспортировать страницы, открытые пользователям и краулерам, будем с помощью инструмента « Анализ сайта » SE Ranking.
Чтобы поисковый робот просканировал все необходимые страницы, выберем нужные параметры в настройках.
Заходим в Настройки → Источник страниц для анализа сайта и разрешаем системе сканировать Страницы сайта, Поддомены сайта и XML карту сайта. Так инструмент отследит все страницы сайта, включая поддомены.
Дальше переходим в раздел Правила сканирования страниц и разрешаем учитывать директивы robots.txt.
Осталось нажать кнопку Сохранить.
Затем переходим во вкладку Обзор и запускаем анализ — нажимаем кнопку Перезапустить аудит.
Когда анализ завершится, на главном дашборде нажимаем на зеленую линию в разделе Индексация страниц.
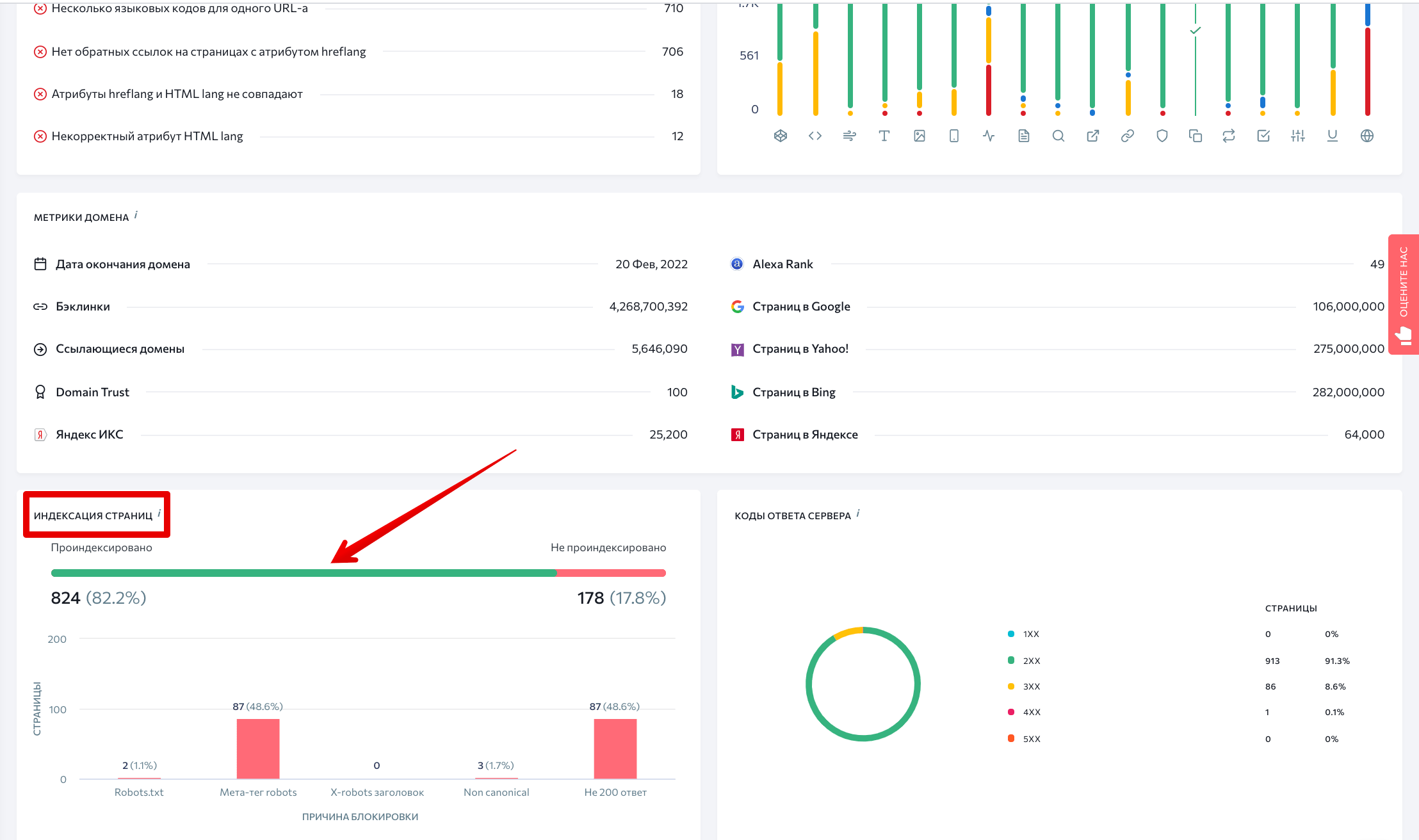
Вы увидите полный список страниц, открытых для поисковых роботов. Теперь можно выгрузить данные — нажимаем на кнопку Экспорт.
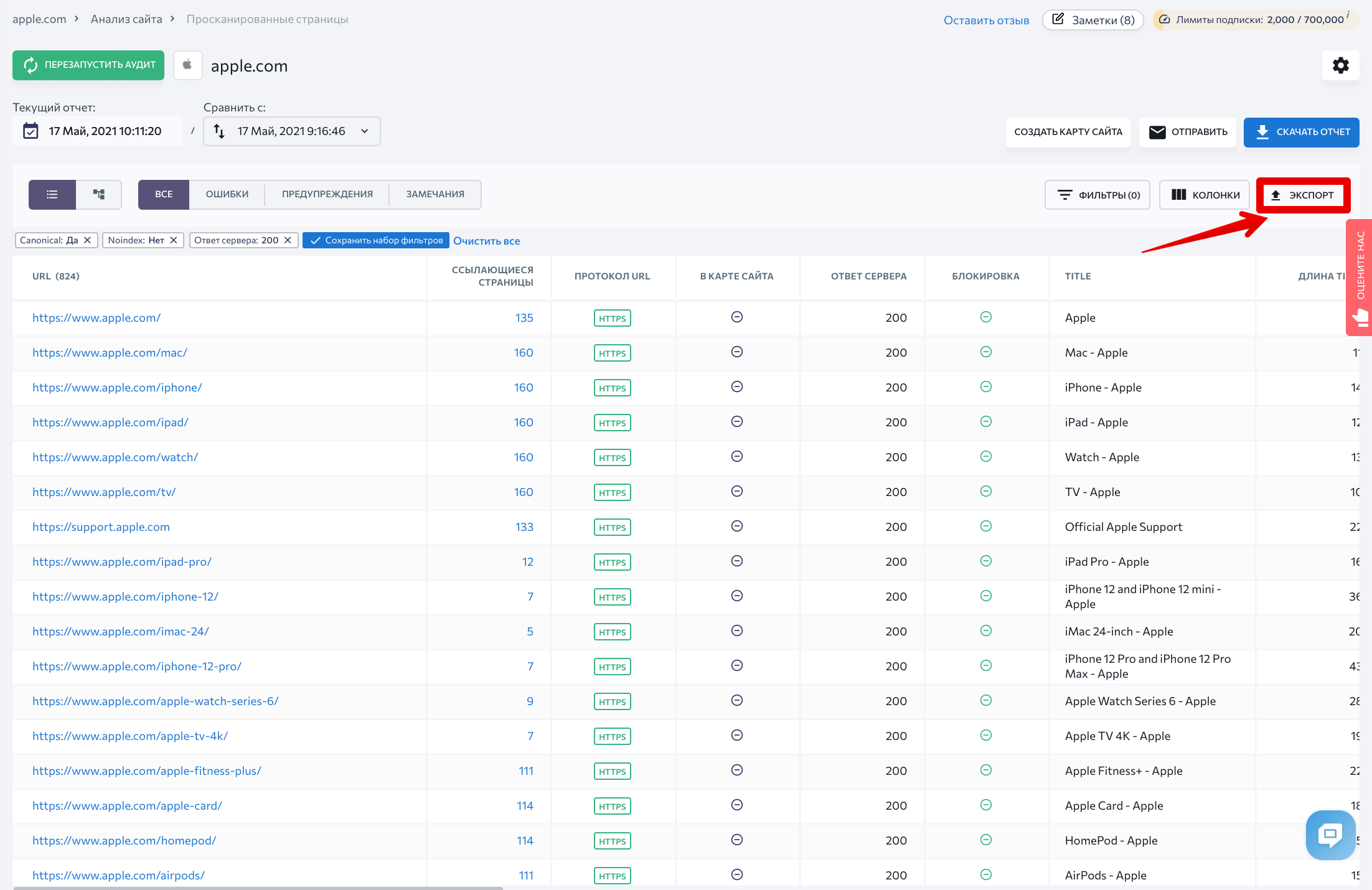
На следующем этапе мы будем сравнивать большие массивы данных. Если вам удобно это делать в Excel — оставляйте все как есть. Если вы предпочитаете Google таблицы, скопируйте оставшиеся строки и вставьте их в новую таблицу.
Через Google Analytics ищем все страницы с просмотрами
Поисковые роботы находят страницы переходя по внутренним ссылкам сайта. Поэтому если на страницу не ведет ни одна ссылка на сайте, кроулер ее не найдет.
Обнаружить их можно с помощью данных из Google Analytics — система хранит инфу о посещениях всех страниц. Одно плохо — GA не знает о тех просмотрах, которые были до того, как вы подключили аналитику к вашему сайту.
Просмотров у таких страниц будет немного, потому что с сайта на них перейти не получится. Находим их следующим образом.
Заходим в Поведение → Контент сайта → Все страницы. Если ваш сайт не молодой, стоит указать данные за какой период вы хотите получить. Это важно, так как Google Analytics применяет выборку данных — то есть анализирует не всю информацию, а только ее часть.


Двигайтесь вниз по списку, пока не увидите страницы, у которых просмотров существенно больше. Это уже страницы с настроенной перелинковкой.
Выделяем страницы-сироты
Наш следующий шаг — сравнить данные из SE Ranking и Google Analytics, чтобы понять, к каким страницам у поисковых роботов нет доступа.
Из Google Analytics мы выгрузили только окончания URL, а нам нужно, чтобы все данные были в одном формате. Поэтому в колонку B вставляем адрес главной страницы сайта как показано на скриншоте.

Далее, с помощью функции сцепить (concatenate) объединяем значения из колонок B и C в колонке D и протягиваем формулу вниз до конца списка.

А теперь самое интересное: будем сравнивать колонку «SE Ranking» и колонку «GA URLs», чтобы найти страницы-сироты.
На практике страниц будет намного больше, чем на скриншоте, поэтому анализировать их вручную пришлось бы бесконечно долго. К счастью, существует функция поискпоз (match), которая позволяет определить, какие значения из колонки «GA URLs» есть в колонке «SE Ranking». Вводим функцию в колонке E и протягиваем ее вниз до конца списка.
Результат должен выглядеть так:

В колонке E увидим, каких страниц из GA нет в колонке SE Ranking, там таблица выдаст ошибку (#N/A). В примере видно, что в ячейке E9 нет значения, потому что ячейка A11 — пустая.
Ваш список будет намного больше. Чтобы собрать все ошибки, отсортируйте данные в колонке E по алфавиту:

Теперь у вас есть полный список страниц, не связанных ссылками с сайтом. Перед тем, как двигаться дальше, изучите каждую одинокую страницу. Ваша цель — понять, что это за страница, какова ее роль, и почему на нее не ведет ни одна ссылка.
Дальше есть три варианта развития событий:
Поработав с изолированными страницами, можно еще раз выгрузить и сравнить списки из SE Ranking и GA. Так вы убедитесь, что ничего не упустили.
Ищем оставшиеся страницы через Google Search Console
Как найти страницы, не связанные ссылками с сайтом, разобрались. Приступим к остальным страницам, о которых знает Google, — будем анализировать данные Google Search Console.
Для начала откройте свой аккаунт и зайдите в раздел Покрытие. Убедитесь, что выбран режим отображения данных «Все обработанные страницы» и откройте вкладку «Страницы без ошибок».

Таким образом в список попадут Проиндексированные страницы, которых нет в карте сайта, а также Отправленные и проиндексированные страницы.

Кликните на список, чтобы развернуть его. Внимательно изучите данные: возможно в списке есть страницы, которые вы не видели в выгрузках из SE Ranking и GA. В таком случае убедитесь, что они должным образом выполняют свою роль в рамках вашего сайта.
Теперь перейдем во вкладку Исключено, чтобы отобразились только непроиндексированные страницы.

Чаще всего страницы из этой вкладки были намеренно заблокированы владельцами сайта — это страницы с переадресациями, закрытые тегом «noindex», заблокированные в файле robots.txt, и так далее. Также в этой вкладке можно выявить технические ошибки, которые нужно исправить.

Если обнаружите страницы, которые вам не встречались на предыдущих этапах, добавьте их в общий список. Таким образом, вы наконец получите список всех без исключения страниц вашего сайта.
В заключение
Если у вас есть доступ к необходимым инструментам, собрать все страницы сайта не сложно. Да, сделать все в два клика не получится, но в процессе сбора данных вы найдете страницы, о существовании которых могли и не догадываться.
Страницы, которые не видят ни поисковые роботы, ни пользователи, не приносят сайту никакой пользы. Так же как и страницы, которые не индексируются из-за технических ошибок. Если таких страниц на сайте много, это может негативно сказаться на результатах SEO.
Хотя бы один раз собрать все страницы сайта нужно обязательно, чтобы адекватно его оценивать и знать, откуда ждать проблем 🙂


