Таблица URL кодов символов кодировки ASCII
Кодирование URL конвертирует символы в формат, который можно безопасно передать в качестве URL-адреса ресурса через интернет.
URL — это Единый указатель ресурсов (англ. Uniform Resource Locator). Веб-браузеры запрашивают HTML-документы с сервера, используя URL-адрес.
URL — это адрес веб-страницы, например: http://www.wm-school.ru
Кодирование URL
URL-адрес ресурса отправляется в интернет в ASCII-кодировке.
Если в URL содержатся символы, не входящие в ASCII-кодировку, URL конвертируется. Перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы. Кодирование URL конвертирует этот адрес в ASCII формат.
Кодировщик URL заменяет небезопасные символы ASCII знаком (%), за которым следуют два шестнадцатиричных числа, которые соответствуют значениям символов из кодировки ISO-8859-1. URL не должен содержать пробелы. Кодировщик URL обычно заменяет пробелы знаком (%20).
URL-коды специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
Таблица URL-кодов специальных (управляющих) символов
URL-коды символов ISO-Latin (диапазон 128-255)
Символы в диапазоне с 128 по 255 отводятся для специфических символов букв алфавитов западно-европейских языков, символов псевдографики, некоторых букв греческого алфавита, а также ряда математических и финансовых символов.
URL-коды символов ISO-Latin (диапазон 128-255)
Зарезервированные символы
Зарезервированные символы — это специальные символы, такие как знак доллара, амперсанд, плюс, слэш, двоеточие, точка с запятой, знак равенства, знак вопроса, знак эт (собака). Все они могут иметь различные значения в URL, поэтому должны быть закодированы.
Таблица URL-кодов зарезервированных символов
Небезопасные символы
Небезопасные символы — это пробел, кавычки, знак меньше, знак больше, знак диез, знак проценты, фигурные скобки, прямой слэш, обратный слэш, тильда, квдратные скобки, гравис. Эти символы также должны всегда быть закодированы.
Что такое URL адрес сайта? Параметры и допустимые символы URL


Параметры и допустимые символы URL адреса сайта
В одной из предыдущих статей я описывал человеко-понятные урл — ЧПУ URL и разное отношение поисковиков к ним. В данной статье хотелось бы рассмотреть само понятие УРЛ, так как оно является основополагающим для всего Интернета.
URL (Uniform Resource Locator) — переводится с английского как Унифицированный указатель ресурса, или Единообразный (универсальный) локатор ресурса, т.е. это путь, по которому можно найти любой файл и каталог в сети Интернет.
URL адрес страницы сайта состоит из следующих элементов: протокол://полное доменное имя/(папка(и))/имя ресурса (файла). В расширенном варианте УРЛ может выглядеть так:
схема://логин:пароль@хост:порт/(папка(и))/имя ресурса (файла)?параметры#якорь
Основные параметры Урл:
Пример из WordPress’а
Допустимые символы URL
В URL адресе допустимы только латинские буквы, арабские цифры и ограниченный набор знаков препинания:
Также возможны запятые (,) и точки с запятой (;), но используются они редко и обычно кодируются, как и все остальные символы (русские буквы, пробелы и т.п.). Яркий пример закодированных урл’ов — статьи Википедии — http://ru.wikipedia.org/wiki/%D0%95%D0%B6.
Правила кодирования нелатинских букв (в т.ч. кириллицы) и прочих не допустимых символов URL: сначала буква кодируется в UTF-8 (кодировку Unicode) — получается 2 байта из каждого символа. Затем каждый из этих байтов преобразуется в шестнадцатиричную систему счисления и перед ним ставится знак процента (%), получается что-нибудь такое: %D0%95%D0%B6 (по-русски будет «еж»). Недопустимые знаки препинания кодируются так:

Кодирование символов в адресах. Справка из Википедии (кликабельно)
Среди УРЛ выделяют относительные и абсолютные, а также статические и динамические URL адреса страниц сайта. Об этом будет рассказано в следующих статьях.
Символы, разрешенные в URL
кто-нибудь знает полный список символов, которые можно использовать в вам без кодирования? На данный момент я использую A-Z a-z и 0-9. но я хочу узнать полный список.
меня также интересует, есть ли спецификация, выпущенная для предстоящего добавления китайских, арабских url-адресов (как очевидно, что это будет иметь большое влияние на мой вопрос)
8 ответов
EDIT: Как правильно указывает @Jukka K. Korpela, этот RFC был обновлен RFC 3986. Это расширило и прояснило символы, действительные для хоста, к сожалению, его нелегко скопировать и вставить, но я сделаю лучший.
в первом согласованном порядке:
символы, разрешенные в URI, зарезервированы или не защищены (или символ процента как часть процентной кодировки)
говорит это RFC 3986 незарезервированных символов (sec. 2.3) а также зарезервированные символы (sec 2.2), если они должны сохранить свое особое значение. А также процентный характер как часть процента-кодирование.
полный список 66 неограниченных символов находится в RFC3986, здесь:http://tools.ietf.org/html/rfc3986#section-2.3
— Это любой символ в следующем наборе:
я протестировал его, запросив мой веб-сайт (apache) со всеми доступными символами на моей немецкой клавиатуре в качестве параметра URL:
они не были закодированы:
не закодировано после urlencode() :
не закодировано после rawurlencode() :
Примечание: перед PHP 5.3.0 rawurlencode() закодированных
из-за RFC 1738. Но это было заменено RFC 3986 так что его безопасно использовать, сейчас. но я не понимаю, почему например <> кодируются с помощью rawurlencode() потому что они не упоминаются в RFC 3986.
дополнительный тест, который я сделал, касался автоматического связывания в почтовых текстах. Я тестировал Mozilla Thunderbird, aol.com, outlook.com, gmail.com, gmx.de и yahoo.de и они полностью связали url, содержащие эти символы:
некоторые люди теперь предложили бы к используйте только rawurlencode() chars, но вы когда-нибудь слышали, что у кого-то были проблемы с открытием этих сайтов?
наконец, я бы сказал, что это нормально использовать эти unencoded:
URI — сложно о простом (Часть 1)

Появилось таки некоторое количество времени, и я решил написать сий пост, идея которого возникла уже давно.
Связан он будет будет с такой, казалось бы, простой вещью, как URI, детальному рассмотрению которой в рунете уделяется как-то мало внимания.
«Пфф, ссылки они и в Африке ссылки, чего тут разбираться?» — скажете вы, тогда я задам вопрос:
Перед тем как начать хотел бы обозначить, что есть пост на схожую тему, в котором все обозначено проще и немного понятнее. Целью же этого поста, я ставлю более глубокое изучение вопроса и сбор информации об URI в одном месте, дабы «не потерять». Ну, почти в одном месте, статья будет разделена на две части
А для удобства бахнем оглавление, которое работает не без особенностей URI, которую мы рассмотрим попозжа, в этой статье.
Ознакомление
1. URI
Унифицированный Идентификатор Ресурса, в простонародье — URI
Самое свежее описание того, чем же все-таки являются эти пресловутые URI датируется январем аж 2005-го, а именно RFC3986, написанный самим Тимом Бёнесом-Ли, родоначальника всеми нами любимого тырнета.
Резюмируя п.1.1 можно сформулировать определение:
Многие из вас замечали, что на разных ресурсах ссылки называют то URL, то URI и, вероятно, становилось интересно — какой же из вариантов правильный?
Дело в том, что URL увидел свет и был документирован в 1990 году, в то время как URI был документирован лишь в 1994 году. И вплоть до 2002 года, до выхода RFC3305, уместными были оба варианта именования, что, порой вносило путаницу.
В п.2 RFC3305 сообщается об устаревании такого термина как URL, применимо к ссылкам, и что отныне верным будет именование URI, с того момента, во всех документах W3C использует термин URI. Исходя из этого, применяя термин URL к соответствующим ссылкам, вы не делаете смысловой ошибки, но делаете ее с точки зрения правильного именования.
Так же примечателен тот момент, что вплоть до выхода RFC2396, в 1997 году, URI расшифровывался как Universal Resource Identifier, что можно увидеть в RFC1630
1.1. Синтаксис
URI составлен из ограниченного набора символов, состоящих из цифр, букв и нескольких графических символов, все эти символы вписываются в кодировку US-ASCII (ASCII). Зарезервированное подмножество символов может использоваться, чтобы разграничить компоненты синтаксиса в URI, в то время как остающиеся символы: не зарезервированный набор и включая те зарезервированные символы, которые не действуют как разделители в данной компоненте URI, определяют данные идентификации каждого компонента.
Зарезервированные символы
Не зарезервированные символы
Для данного случая, согласно ABNF :
ALPHA — любая буква верхнего и нижнего регистров кодировки ASCII (в regExp [A-Za-z])
DIGIT — любая цифра (в regExp 4)
HEXDIG — шестнадцатиричная цифра (в regExp [0-9A-F])
Процентное кодирование
Т.о., %20, например, означает пробел.
1.2. Компоненты URI
где в квадратных скобках опциональные компоненты
Переходя по указанной в оглавлении ссылке, браузер производит переход ко вторичному ресурсу относительно данной страницы, т.е. скроллит вниз, до появления нужного на экране.
На этом, пожалуй, знакомство с URI можно закончить и начать углубляться в отдельные подвиды URI, а именно
2. URL
URL используются, чтобы определить местоположение ресурсов, обеспечивая абстрактную идентификацию расположения ресурса. Определив местоположение ресурса, система может выполнить множество операций на ресурсе, которые могут быть характеризованы такими словами как ‘доступ’, ‘обновление’, ‘замена’, ‘поиск атрибутов’. В целом только метод доступа должен быть определен для любой схемы URL.
2.1. Структура
В целом, URL имеет схожую структуру, для всех схем, хотя для каждой отдельно взятой схемы, структура может отличаться от общего шаблона.
Графически ее можно выразить в следующем виде: 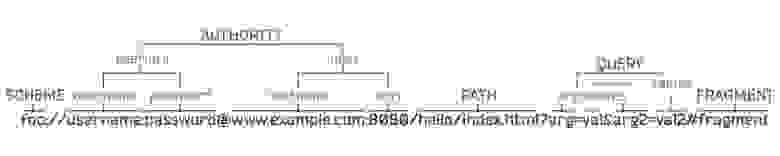
3. URN
Унифицированные имена ресурсов (URN) предназначены, чтобы служить постоянными, независимыми от расположения, идентификаторами ресурсов и разработаны для упрощения отображения других пространств имен (которые совместно используют свойства URN) в URN-пространство. Таким образом, синтаксис URN обеспечивает средство закодировать символьные данные в форме, которая может быть отправлена посредством существующих протоколов, записана при помощи большинства клавиатур, и т.д.
3.1. Структура
Самоидентифицирующийся URN
Такие URN содержат в NID название хэш-функции, а в NSS значение хэша, вычисленного для идентифицируемого объекта. Такие ссылки используются в magnet-ссылках и заголовках p2p-сети Gnutela2.
Например, URN из magnet-ссылки с одного торрент-трекера:
magnet:?xt=urn:btih:c68abc1ba9b8c7c4bc373862cad1a8c01d69e53d.
С теорией все, во второй части рассмотрим, что можно и что нужно делать с URI, если мы их обрабатываем, а именно — нормализация, разбор и т.д.
За сим откланяюсь, спасибо что читали, надеюсь не было скучно, удачи!
Мой URL — это не ваш URL

Когда давным-давно в 1996 году я приступил к работе над программой httpget, предшественницей проекта Curl, я написал свой первый синтаксический анализатор URL. Как раз тогда этот универсальный адрес получил название URL: Uniform Resource Locator (единый указатель ресурсов). Его спецификация была опубликована IETF в 1994 году. Аббревиатура «URL» была затем использована как источник вдохновения для названия инструмента и проекта Curl.
Термин «URL» был позднее изменён; его стали называть URI (Uniform Resource Identifier — единый идентификатор ресурсов), согласно спецификации, опубликованной в 2005 году, однако основное сохранилось: синтаксис для строки, задающей онлайн-ресурс и указывающей протокол для получения этого ресурса. Мы требуем, чтобы curl принимал указатели URL, как определено данной спецификацией RFC 3986. Ниже я расскажу, почему на самом деле это не совсем так.
Был ещё родственный RFC, описывающий IRI: Internationalized Resource Identifier (международный идентификатор ресурсов). IRI, по существу, то же самое, что URI, но IRI позволяют использовать символы, не входящие в ASCII.
Консорциум WHATWG позднее создал свою собственную спецификацию URL, в основном, сведя вместе форматы и идеи от URI и IRI с сильным упором на браузеры (что неудивительно). Одна из объявленных ими целей — «Модернизировать RFC 3986 и RFC 3987 в соответствии с современными реализациями и постепенно вывести их из употребления». Они хотят вернуться к использованию термина «URL», справедливо заявляя, что термины URI и IRI просто запутывают ситуацию и что люди так и не поняли их (или часто даже не знают, что эти термины существуют).
Спецификация WHATWG написана в духе старой доброй мантры браузеров: быть как можно более либеральными с пользователями, всегда пытаться угадать, что они имеют в виду, и выворачиваться наизнанку, пытаясь сделать это. Хотя при этом мы все знаем сейчас, что закон Постеля — не самый лучший подход к делу. На деле это значит, что спецификация позволяет использовать в URL слишком много слэшей, пробелы и символы, не входящие в ASCII.
С моей точки зрения, такую спецификацию также очень трудно читать и соблюдать, поскольку она не очень подробно описывает синтаксис или формат, но при этом навязывает обязательный алгоритм парсинга. Чтобы проверить моё утверждение: посмотрите, что это спецификация говорит о концевой точке после имени хоста в URL.
Вдобавок ко всем этим стандартам и спецификациям, в интерфейсе всех браузеров есть адресная строка (которую часто называют и по-другому), которая позволяет пользователям вводить какие угодно забавные строки и преобразовывает их в URL. Если ввести » http://localhost/%41 » в адресную строку, то участок с процентом будет преобразован в «A» (поскольку 41 в шестнадцатеричном исчислении является заглавной буквой A в ASCII), но если ввести » http://localhost/A A «, то фактически в исходящий HTTP-запрос GET будет отправлено » /A%20A » (с пробелом в URL-кодировке). Я говорю об этом, так как люди часто думают, что всё, что можно ввести в эту строку — и есть URL.
Указанное выше — в основном моё (искаженное) представление, с какими спецификациями и стандартами нам пока приходится работать. Теперь давайте добавим реальности и посмотрим, какие проблемы мы получаем, когда мой URL — это не ваш URL.
Так что же такое URL?
Или более конкретно — как мы пишем их? Какой синтаксис используем?
Думаю, одна из самых больших ошибок в спецификации WHATWG (и в ней причина, почему я выступаю против этой спецификации в её текущей форме с твёрдым убеждением, что они неправы) состоит в том, что они полагают, будто только им позволено работать с URL и давать им определение; они ограничивают свое представление об URL исключительно браузерами, HTML и адресными строками. Конечно, WHATWG создан большими компаниями, представляющими браузеры, которые использует почти каждый, а в этих браузерах широко работают указатели URL, но сами URL — явление значительно большее.
Представление об URL, существующее у WHATWG, не слишком широко принимается за пределами браузеров.
Двоеточие-слэш-слэш
Если спросить пользователей — обычных людей без какого-либо особого знания протоколов или сети — о том, что такое URL, то что они ответят? Последовательность «://» (двоеточие-слэш-слэш) была бы в начале списка ответов; несколько лет назад, когда браузеры показывали URL более полно, это было бы еще заметнее. Увидев эту последовательность, мы сразу понимаем, что перед нами именно URL.
Однако давайте отойдём от пользователей и оглядимся — в мире существуют почтовые клиенты, эмуляторы терминалов, текстовые редакторы, Perl-скрипты и многое-многое другое, что способно распознавать URL и работать с ними. Например, открыть URL в браузере, превратить в активную ссылку в сгенерированном HTML и так далее. Огромное количество названных скриптов и программ будет использовать именно последовательность «двоеточие-слэш-слэш» как главный признак.
Спецификация WHATWG говорит, что должен быть как минимум один слэш и что парсер при этом обязан принимать какое угодно количество слэшей. Это значит, что » http:/example.com » и » http:///////////////example.com » — полностью подходящие варианты. RFC 3986 и многие другие с этим не согласны. Ну, действительно, большинство из людей, с которыми я спорил последние несколько дней, даже те, кто работает в вебе, говорит, думает и убеждено, что URL имеет два слэша. Просто посмотрите внимательнее на скриншот результата поиска картинок в Гугл по запросу «URL» выше в этой статье.
Мы просто знаем, что у URL есть два слэша (хотя, да, URL типа file: обычно имеют три слэша, но давайте пока проигнорируем это). Не один. Не три. Два. Но WHATWG с этим не согласен.
«Есть хоть одна настоящая причина принимать более двух слэшей для не-файловых URL?» (спрашиваю я раздраженно у членов WHATWG)
Спецификация говорит это, потому что браузеры реализовали её именно так.
Никакое лучшее объяснение не было дано даже после того, как я указал, что это утверждение неправильное и далеко не все браузеры делают так. Возможно, эта ветка обсуждения покажется вам весьма познавательной.
В проекте Curl мы как раз недавно начали обсуждать, как обращаться с указателями URL, имеющими число слэшей, отличное от двух, потому что, оказывается, уже есть серверы, передающие обратно такие URL в заголовке “Location:”, и некоторые браузеры без возражений принимают их. Curl — нет, так же как и большинство из множества других библиотек и инструментов командной строки. Кого нам поддержать?
Пробелы
Символ пробела (код 32 в ASCII, шестнадцатеричный код 0x20) не может быть частью URL. Если требуется отправить его, то следует использовать URL-кодировку, как это делают с любым другим недопустимым символом, который надо сделать частью URL. URL-кодировка — это байтовое значение в шестнадцатеричном исчислении со знаком процента перед ним. Таким образом, «%20» означает пробел. Это также означает, что синтаксический анализатор, например, сканирующий текст на предмет указателей URL, узнаёт, что достиг конца URL, когда он обнаруживает недопустимый символ. Например, пробел.
Браузеры обычно преобразовывают все %20 в своих адресных строках в символ пробела, чтобы ссылки выглядели прилично. При копировании адреса в буфер и вставке его в текстовый редактор мы видим пробелы как %20, что и требуется.
Я не уверен, в этом ли причина, но браузеры также принимают пробелы как часть URL, получая, например, переадресацию в HTTP-ответе. Такие URL передаются от сервера к клиенту в заголовке «Location:». Браузеры без проблем допускают пробелы в них URL, кодируя их в виде %20 и отправляя следующий запрос. Это заставляет curl принимать пробелы в перенаправляемых «URL».
Не-ASCII
Поддержка в URL языков, включающих символы, не входящие в ASCII, конечно, важно, особенно для незападных сообществ, и я согласен, что спецификация IRI никогда не была достаточно хороша. Я лично далёко не эксперт в интернационализации, поэтому я руководствуюсь тем, что слышал от других. Но, конечно, пользователи нелатинских алфавитов и систем печати должны иметь возможность записывать свои «интернет-адреса» в ресурсы и использовать их как ссылки.
В идеальном случае у нас была бы интернационализированная версия для показа пользователю, и версия в кодировке ASCII для внутреннего использования в сетевых запросах.
Для международных доменных имён имя преобразуется в кодировку punycode так, чтобы оно могло быть прочитано обычными серверами DNS, которые ничего не знают об именах в кодировке, отличной от ASCII. Идентификаторы URI не имеют IDN-имён; IRI и URL по версии WHATWG — имеют. Сurl поддерживает IDN-имена хостов.
WHATWG заявляет, что URL могут использовать UTF-8, тогда как URI — только ASCII. Curl не воспринимает не-ASCII-символы в части адреса, задающей путь, но кодирует их процентом в исходящих запросах; это порождает “интересные» побочные эффекты, когда не-ASCII-символы представлены в коде, отличном от UTF-8, что является, например, стандартным для Windows.
Подобно тому, что я написал выше, это приводит к серверам, отправляющим назад не-ASCII-коды в HTTP-заголовках, которые браузеры охотно принимают, и не-браузерам тоже приходится работать с ними.
Стандарта URL не существует
Я не пытался представить полный список проблем или несоответствий — здесь просто некоторая подборка трудностей, с которыми я недавно столкнулся. «URL», выданный в одном месте, конечно, совсем необязательно будет принят или понят в другом месте как «URL».
В наши дни даже curl уже не следует строго ни одной опубликованной спецификации — мы медленно деградируем в угоду “веб-совместимости”.
Единый стандарт URL отсутствует, и какая-либо работа в этом направлении не ведётся. Я не могу считать, что WHATWG прилагает настоящие усилия к этому, поскольку она пишет спецификацию закрытой группой без серьёзных попыток привлечь более широкое сообщество.


